









")

INSTALAÇÃO ARCH LINUX - BIOS-Legacy, Triple-Boot, XFCE, /home, games


Página 2 de 7 •  1, 2, 3, 4, 5, 6, 7
1, 2, 3, 4, 5, 6, 7 

 PÁGINA 2
PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:27 pm
por ADRIANNO Ter 07 Nov 2023, 1:27 pm

Última edição por ADRIANNO em Qua 15 Nov 2023, 3:42 pm, editado 4 vez(es)

ADRIANNO- Honrado

-

Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -



PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:28 pm
por ADRIANNO Ter 07 Nov 2023, 1:28 pm
Última edição por ADRIANNO em Qua 15 Nov 2023, 4:39 pm, editado 3 vez(es)
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:28 pm
por ADRIANNO Ter 07 Nov 2023, 1:28 pm
 VOLTAR AO ÍNDICE
VOLTAR AO ÍNDICE PRÓXIMA PÁGINA
PRÓXIMA PÁGINA PERMISSÃO DE ACESSO wiki
PERMISSÃO DE ACESSO wikiCalculadora CHMOD
Existem três tipos de usuários:
DONO = É o usuário que criou ou copiou o arquivo.
GRUPO = É um conjunto de usuários que têm a permissão do dono.
OUTROS = são os usuários que não fazem parte do grupo do dono.
ROOT = Deidade, com poderes para tocar no hardware.
As permissões são aplicadas para cada tipo de usuário.
Tem três formas de visualizar as permissões:
1) Modo de permissão simbólico = drwx
d=directory (d no início sinaliza um diretório)
r=read (leitura)
w=write (escrever)
x=run (execute)
2) Modo de permissão octal:〔0〕〔1〕〔2〕〔3〕〔4〕〔5〕〔6〕〔7〕
Cada grupo de três bits em um número binário corresponde a um dígito octal.
Binário 000 corresponde a Octal 0
Binário 001 corresponde a Octal 1
Binário 010 corresponde a Octal 2
Binário 011 corresponde a Octal 3
Binário 100 corresponde a Octal 4
Binário 101 corresponde a Octal 5
Binário 110 corresponde a Octal 6
Binário 111 corresponde a Octal 7
3) Modo de permissão binário: 1 ou 0, indicando se a permissão está ligada ou desligada,
Os números binários são agrupados em grupos de três dígitos a partir da direita.
dono grupo outros
rwx__rwx__rwx_OCTAL
000 000 000〔000〕d--------- ➪(não lê, não escreve, não executa)
001 001 001〔111〕d--x--x--x ➪(executa)
010 010 010〔222〕d-w--w--w- ➪(escreve)
011 011 011〔333〕d-wx-wx-wx ➪(escreve, executa)
100 100 100〔444〕dr--r--r-- ➪(lê)
101 101 101〔555〕dr-xr-xr-x ➪(lê, executa)
110 110 110〔666〕drw-rw-rw- ➪(lê, escreve)
111 111 111〔777〕drwxrwxrwx ➪(lê, escreve, executa)
-=archive (traço no início sinaliza que é um arquivo)

d=directory (d no início sinaliza um diretório)
l=link (L no início indica que é um link simbólico)
-=Nenhuma permissão de acesso


Vamos testar isso na prática:
Criaremos um script Bash no diretório atual
touch script2000.sh
agora temos um arquivo chamado script2000.sh
Você pode deixar o arquivo vazio, já que estamos apenas testando as permissões,
mas que tal tornarmos as coisas mais divertidas e editarmos o arquivo?
nano script2000.sh
Experimente copiar e colar esse código para seu script2000.sh
Assim, você poderá criar um divertido jogo de adivinhação.
Esse jogo gera um número aleatório entre 0 e 99 e pede ao jogador para adivinhar o número correto.
Ele fornece feedback se o palpite é muito alto ou muito baixo e conta o número de tentativas até que o jogador adivinhe corretamente.
- Código:
#!/bin/bash
secret=$((RANDOM % 100))
attempts=0
echo "Bem-vindo ao jogo de adivinhação!"
while true; do
read -p "Digite um número: " guess
((attempts++))
if [[ $guess -eq $secret ]]; then
echo "Parabéns! Você acertou em $attempts tentativas."
break
elif [[ $guess -lt $secret ]]; then
echo "Tente um número maior."
else
echo "Tente um número menor."
fi
done

Vamos tornar o script executável
chmod +x script2000.sh
olhe as permissões atuais do arquivo:
ls -l script2000.sh

-rwxr-xr-x ou 755
7 DONO - (lê, escreve, executa)
5 GRUPO - (lê, executa)
5 OUTROS - (lê, executa)
Vamos mudar as permissão desse arquivo:
chmod 631 script2000.sh
olhe as permissões atuais do arquivo:
ls -l script2000.sh

-rw--wx--x ou 631
6 DONO - (lê, escreve)
3 GRUPO - (escreve, executa)
1 OUTROS - (executa)
vamos testar, abrindo o arquivo
./script2000.sh
Obs: Cada usuário possui um grupo com o mesmo nome, e por padrão, o arquivo é sempre atribuído à propriedade de seu criador.
No entanto, neste caso, removemos o privilégio de execução do proprietário do arquivo script2000.sh, mas ainda temos permissão para ler e escrever nele.


As regras que o dono estabelece para seus arquivos são soberanas, para com outros usuários, ou ele mesmo.
Usuários locais, virtuais, remotos ou de containers(docker.), todos com seus devidos poderes.
É possível determinar regras para o shadow restringir de onde um usuário poderá fazer login.
Essa elevação de privilégios confere aos usuários autorizados a capacidade de executar comandos.
Isso torna o sistema bastante punitivo contra vírus, quando aliada à criptografia de arquivos, essa medida acrescenta uma camada adicional de proteção ao seu sistema.
A diversidade do ecossistema Linux exige um esforço sobrenatural de um malware para se espalhar com sucesso.O Ciclo de Um Vírus no Linux:
Tudo começa quando o arquivo contendo um vírus projetado especificamente para infectar sistema Linux é baixado. Para dar uma mãozinha ao vírus, decidimos executá-lo com privilégios de root. Sua primeira ação é descompactar automaticamente em um diretório, mas logo descobrimos um contratempo: a falta de permissões de gravação nesse diretório impediu o malware de prosseguir. O vírus estava programado para descompactar, mas infelizmente o destino escolhido não permitia gravação, pois era um diretório com permissão chmod 000.
Decidimos dar uma segunda chance ao vírus. Recompilamos o código e o executamos na pasta do usuário, dessa vez garantindo todas as permissões necessárias. Porém, o vírus enfrentou outro obstáculo: ele dependia de uma biblioteca específica que não estava disponível no sistema. Para ajudá-lo novamente, compilamos e criamos um pacote .deb a partir do código-fonte, incluindo todas as dependências necessárias para o vírus funcionar.
Finalmente, o vírus conseguiu ser executado, mas, inesperadamente, gerou logs de erro, resultando em uma falha que causou um despejo de núcleo e travou. Após uma hora de análise minuciosa dos logs, descobrimos que o vírus presumiu incorretamente que estava em um sistema de arquivos ext4, o que gerou problemas, uma vez que, na verdade, estávamos utilizando o sistema de arquivos Btrfs, que o fez operar em modo leitura.
Infectar todos os sistemas Linux é uma tarefa impossível, e até mesmo atingir toda a base de usuários de uma distribuição seria um desafio hercúleo.
Agora, pense em tentar infectar aquele indivíduo que está usando uma distribuição baseada no Arch, com um kernel do FreeBSD,
em um sistema de arquivos que é um fork, em uma interface gráfica esotérica com algumas variáveis de ambiente modificadas, exemplo:
HOME=/pôneis/seu_nome_de_usuário, um gerenciador de pacotes personalizado e um conjunto de permissões cuidadosamente ajustado.
Isso é apenas o começo das complexidades que um vírus enfrentaria.
Gostaria de lhe apresentar as ferramentas que temporariamente conferem esses poderes a um usuário comum:
sudo
Ao digitar sudo antes de um comando permite que um usuário comum ganhe a capacidade de executar tarefas administrativas
sem a necessidade de efetuar o login na conta de superusuário (root) do sistema, conforme definido pela política de segurança.
Se você tentar executar um comando administrativo usando uma conta de usuário comum, receberá a seguinte mensagem de erro:
erro: você não pode realizar esta operação a menos que seja root.
exemplo:
Vamos fazer um teste; crie um arquivo de texto chamado meuarquivo.txt contendo Fórum Flyer dentro de um diretório do sistema /etc
Espere, você não tem permissão para fazer isso! então, o comando sudo é para essas ocasiões, vamos usa-lo:
sudo echo "Fórum Flyer" > /etc/meuarquivo.txt
(será solicitado uma senha)
O sudo sairá se a senha do usuário não for inserida dentro de um limite de tempo, além de inspirar.
Mas oferecee suporte ao cache de credenciais, permitindo que o usuário execute o sudo novamente dentro de um período.
Ao usar o comando sudo -v, um usuário pode atualizar o tempo das credenciais de cache.
sudo -K remover todas as credenciais cacheadas do usuário.
sudo -N comando Para executar um comando que não atualiza as credenciais cacheadas do usuário.
O comando sudo não está incluído no conjunto de programas essenciais do Arch Linux.
Para permitir que todos os usuários possam utilizá-lo, é necessário que o superusuário (root) o instale.
pacman -S sudo
Lista os privilégios do usuário atual
sudo -l
Para executar um comando como se você fizesse parte de um grupo específico:
sudo -g grupo comando
Você pode iniciar um novo shell como superusuário (root), concedendo a si mesmo todos os privilégios administrativos. Basta utilizar o comando:
sudo -i
A opção -i inicia um novo shell de login com um ambiente semelhante ao de um usuário comum, mas como root.
Configura a variável HOME para o diretório pessoal do superusuário (root).
Além disso, redefine todas as variáveis de ambiente para refletir o ambiente do root.
Mantém um registro de auditoria de quem usou o sudo para iniciar o shell de root.
É a maneira recomendada de obter acesso ao ambiente de root puro.
Outro comando útil é o seguinte:
sudo -Es
Ele mantém a variável de ambiente HOME como o diretório pessoal do usuário original que está executando o comando sudo.
Permitindo que o usuário continue a ter acesso ao seu próprio diretório pessoal proporcionado pela opção -E enquanto executa comandos com privilégios de superusuário.
Essa escolha de design do sudo equilibra a segurança com a conveniência, proporcionando um ambiente seguro e preservando o acesso aos recursos pessoais do usuário.
Também vou mencionar o comando:
sudo su
Este comando também inicia um shell de root.
Algumas variáveis de ambiente do usuário original ainda permanecem ativas no ambiente de root.
Mantém um registro de auditoria das ações realizadas como root.
Uma característica peculiar do comando é a herança de alguns aspectos da sessão anterior, como não substituir o diretório pessoal ~ pelo diretório pessoal do superusuário.
sudo é mais apropriado para executar tarefas administrativas temporárias enquanto você permanece autenticado como um usuário comum,
se o sudo for usado com o su quer dizer que o período será prolongado, proporcionando acesso contínuo a todos os recursos e configurações associados ao superusuário.
Independentemente da representação, é importante ressaltar que todos esses comandos, seja sudo su, sudo -i ou sudo -Es, fornecem um ambiente administrativo.
Ambos são úteis, mas a escolha entre eles depende das necessidades específicas e das políticas de segurança do sistema em uso.

Ao executar este script como um usuário comum, você receberá a mensagem "Você está em uma sessão de usuário comum."
Quando você o executa como o superusuário (root), que possui acesso às suas próprias variáveis de ambiente, a mensagem será "Você está em um ambiente root puro."
Aqui está o código:
- Código:
if [ -n "$SUDO_USER" ]; then
echo "Está em um ambiente root puro."
else
echo "Está em uma sessão de usuário comum."
fi
Digamos que você está logado como root e deseja executar um comando sem permissões administrativas.
Use essa estrutura para executar o comando apenas com as permissões de um usuário especifico:
sudo -u username_aqui comando_aqui
sudo -u root ls -l
sudo -u flyer ls -l
Para verificar se o usuário logado possui acesso às variáveis de ambiente, você pode utilizar os seguintes comandos de teste:
echo "HOME: $HOME" = Esta variável armazena o caminho para o diretório pessoal do usuário atual.
echo "USER: $USER" = Contém o nome do usuário atualmente logado no sistema.
echo "SHELL: $SHELL" = Esta variável armazena o caminho para o shell padrão do usuário atual.
echo "PATH: $PATH" = Onde o sistema procura por programas para serem executados.
echo "LANG: $LANG" = Define o idioma padrão que o sistema operacional.
echo "SUDO_USER: $SUDO_USER" = Armazena o nome de usuário que iniciou a sessão do sudo.
- outras variáveis:


Vou demonstrar o uso do parâmetro --preserve-env para mantém as variáveis de ambiente durante a execução de um script ou comando.
Isso pode ser útil em situações onde o script depende dessas variáveis de ambiente específicas para funcionar (como PATH e LANG neste caso)
sudo --preserve-env=PATH,LANG script.sh
Para habilitar o uso do sudo em seu usuário comum, é necessário que o administrador do sistema inclua seu nome de usuário em um arquivo chamado /etc/sudoers
e lhe atribua uma senha especial para essa finalidade específica. Essa nova senha concederá permissões para aplicar configurações no sistema.
Você ficará com duas senhas: A senha para usar o sudo e sua senha principal para fazer o login na sua conta de usuário.
Ferramentas concorrentes do sudo:(Doas download), (pkexec download), runas-git, suex, gosu.
su
Ao contrário do sudo, o su é um comando essencial que já está incluído no pacote util-linux, o qual faz parte do pacote base do sistema.
su é uma abreviação para "substitute user", ou seja, ele permite a troca de usuário, incluindo a capacidade de efetuar login no superusuário (root).
O comportamento do comando su pode ser personalizado e configurado pelo administrador do sistema.
Para utilizar o comando su, basta digitar su seguido pelo nome do usuário desejado, como no exemplo:
su root
su flyer
Ao usar o su e especificar um usuário, será solicitada a senha desse usuário. Se a senha estiver correta, você assumirá a identidade desse usuário durante a sessão.
Esse comando efetivamente inicia um shell com os privilégios de root dentro da sua sessão atual, mantendo as variáveis de ambiente do usuário comum.
Isso é útil quando você precisa realizar tarefas específicas como superusuário temporariamente, mantendo a maior parte do seu ambiente original.
É importante notar que o comando su não configura todas as variáveis de ambiente necessárias para uma sessão root pura.
O sudo e o su estão intrinsecamente ligados à organização dos usuários, especialmente àqueles que necessitam de permissões de acesso diferenciadas.
Vale relembrar os três tipos de usuários principais:
Dono: Este é o usuário que criou o arquivo originalmente ou realizou a cópia. Como dono, ele possui autoridade total sobre o arquivo, incluindo a habilidade de definir permissões.
Grupo: Este é um conjunto de usuários que compartilham determinadas permissões, com base na autorização concedida pelo dono. O grupo pode acessar o arquivo de acordo com as permissões estabelecidas.
Outros: Esses são os usuários que não pertencem ao grupo do dono, as permissões definidas para "outros" se torna um tipo de exclusão para esses usuários.
Você tem a capacidade de conceder permissões de acesso a um arquivo, seja para um usuário específico ou para um grupo composto por diversos usuários.
Isso permite uma gestão fina das autorizações, garantindo que apenas os usuários autorizados tenham acesso aos arquivos.
Para visualizar os grupos existentes em seu sistema:
cat /etc/group
Aqui estão alguns exemplos de grupos do sistema: http, dbus, scanner, network, log ...
Ao adicionar um usuário a qualquer a um desses grupos, ele ganha a capacidade de acessar as funcionalidades associadas a esse hardware específico.
como criar um grupo
groupadd nome_do_grupo
Adicionar um usuário a um grupo
gpasswd -a nome_do_usuário nome_do_grupo
Para além da elevação de privilégios possibilitada pelo uso do sudo, você também pode empregar os comandos chmod, chown e chgrp
para ajustar as permissões de acesso, alterar o proprietário e modificar o grupo associado a um arquivo.
Ao entender como os grupos operam no ecossistema do Linux e como eles se interrelacionam com a elevação de privilégios de usuários,
você adquire o conhecimento de gerenciar seu sistema com extrema segurança para seu dados.
Durante minha demonstração de uma instalação detalhada do Arch Linux, você já pôde vivenciar esses conceitos na prática.
Aqui está um trecho dos comandos que foram utilizados, sobre grupos, sudo, criação de usuário e permissões:
groupadd sudo Cria um novo grupo, chamado sudo.
nano /etc/sudoers Edita o arquivo de configuração do sudo.
sudo ALL=(ALL) ALL remova o símbolo de # dessa linha
useradd -m -G sudo,uucp,vboxusers,log,sys,systemd-journal -s /bin/bash flyer1 Cria seu primeiro usuário, atribuindo ele a vários grupos e ao shell bash.
passwd flyer1 Define uma senha para esse usuário.
chmod 755 -R /media/usb Altera as permissões de um arquivo.
chown -R flyer1 /media/usb Modifica o proprietário de um arquivo.
chgrp -Rc flyer1 /media/usb Altera o grupo associado a um arquivo.
 O Linux organiza os arquivos de forma inteligente e os envia para seus devidos locais.
O Linux organiza os arquivos de forma inteligente e os envia para seus devidos locais.O Filesystem Hierarchy Standard
Ou (FHS) é um projeto da Linux Foundation para padronizar a estrutura de diretórios e o conteúdo dos diretórios nos sistemas Linux.
alguns exemplos.

/ Este é o diretório raiz, o primeiro da hierarquia, essa barra indica o inicio de todos os outros caminhos, todos os outros diretórios ficam dentro dele.
Um sistema de arquivos é comparado a uma árvore; nesse caso, este seria o tronco ao qual todos os galhos se conectam.
/bin é um link simbólico(atalho) para /usr/bin. contendo executáveis de uso comum, Quanto mais programas instalados maior será o tamanho desse diretório.
/sbin é um link simbólico(atalho) para /usr/bin. contendo executáveis que controlam o sistema. Quanto mais programas, maior será o tamanho desse diretório.
- Descrição de Link simbólico:
- Links simbólicos são usados para criar referências simbólicas para arquivos ou diretórios, permitindo que você acesse esses arquivos ou diretórios por meio de um caminho mais conveniente. Quando o arquivo de destino é removido ou alterado, o link simbólico se torna quebrado e não pode mais ser usado para acessar o arquivo ou diretório pretendido.
/usr Com executáveis binários, documentações, bibliotecas, plugins, daemons, etc. 184818 itens. Tamanho 6,4 GiB.
/var diretório de arquivos em cache variáveis e de crescimento exponencial. 5278 itens. Tamanho da pasta 2,0 GiB.
/run arquivos temporários do sistema que são necessários pelos PIDs em execução, sockets, containers, tem um subdiretório chamado /run/user/ com seu ID de usuário como nome do diretório. id -u usuário_aqui contêm informações temporárias relacionadas às sessões e atividades dos usuários, como data e hora da execução do comando sudo.
/dev abreviação de (devices), aqui contém arquivos que representam todos os dispositivos, como por exemplo: os virtuais com suas sessões de pseudoterminais e os de rede para comunicação de VPN, etc. São gerados dinamicamente pelo sistema durante o processo de inicialização e podem variar de acordo com o sistema. Conheça o diretório /dev/null Quando você redireciona a saída de um comando para /dev/null você envia essa saída para o nada, uma espécie de buraco negro no sistema Unix-like, frequentemente usado em scripts e automatização de tarefas para suprimir saídas indesejadas.
/dev/shm, também conhecido como tmpfs, é um sistema de arquivos especial que reside os dados da memória RAM, útil para operações que requerem acesso rápido aos dados, como caches temporários. Quando o sistema é reiniciado, o conteúdo de /dev/shm/ é perdido e precisa ser recriado.
/dev/zero, Este dispositivo é uma fonte de dados zerados. Todos os dados gravados neste dispositivo são descartados. Uma leitura deste dispositivo retornará tantos bytes contendo o valor zero quantos foram solicitados.
/dev/tty, é uma representação simbólica do terminal de controle de um processo. Quando o dispositivo /dev/tty é aberto, todas as operações de leitura e escrita realizadas por esse programa serão direcionadas para o terminal de controle ativo, como se o programa estivesse interagindo em tempo real.
/home arquivos pessoais, como documentos, fotografias, save de games/softwares. Você passará muito tempo controlando o crescimento dessa pasta.
/.cache é um diretório oculto ligado a home do usuário, que armazenamento de dados temporários dos aplicativos. Reduzindo a necessidade de recriar os dados.
/.cache/mesa_shader_cache refere-se ao diretório cache para shaders gerados pelo driver Mesa, que oferecer suporte a aceleração gráfica, como transformações geométricas, cálculos de luz e sombras, texturização, outros. Quando esses shaders são compilados e executados pela primeira vez, o driver gráfico os armazena em cache para acelerar o seu carregamento no futuro, evitando a necessidade de recompilar os shaders sempre que um programa é iniciado, economizando tempo e recursos do sistema.
Outras Pastas: /mnt /srv /root /boot /opt /lib /lib64 /proc /sys /etc /tmp (se somar todas essas outras da 1,4GiB)
no final dessa publicação comentei em forma de lista um guia, para te ajudar a entender as pastas do Linux.
PASTAS IMPORTANTES DO ARCH LINUX
- Código:
Seu kernel fica nessa pasta
/lib/modules
esses arquivos descrevem como um initramfs deve ser construído
/usr/share/libalpm/scripts
para definir preset de inicialização
nano /etc/mkinitcpio.conf
nano /etc/mkinitcpio.d/linux.preset
arquivos de daemon usado pelo systemctl
/etc/systemd/system
Chaves "PGP PUBLIC KEY"
/usr/share/pacman/keyrings
Histórico de todos os comandos que você fez usando o pacman. journal
/var/log
documentações de inúmeros programas instalados
/usr/share/doc
Repositórios são banco de dados usados pelo pacman.
/var/lib/pacman
se você deseja alterar o caminho dos repositórios deve comenta-los aqui:
nano /etc/pacman.conf
Pacotes baixados e armazenados para serem reinstalados localmente, sem internet.
/var/cache/pacman/pkg
lembrando que essa pasta pode ser limpa para abrir espaço em seu HD: sudo pacman -Sc
para reinstalar um pacote dessa pasta ou fazer downgrade use:
sudo pacman -U '/var/cache/pacman/pkg/arch-wiki-docs-20221115-1-any.pkg.tar.zst'
+informações me https://wiki.archlinux.org/title/Downgrading_packages_(Portugu%C3%AAs)
Aqui fica a memória dos aplicativos instalados.
(programas desinstalados ainda guardam os perfis dos usuários.)
ex: Se eu deletar a pasta do meu Streaming de música "Deezer" vou precisar fazer login novamente, resetando o cache que guardava meu perfil.
Fazendo backup dessa pasta, você não precisará fazer login em seus programas, mesmo depois de uma formatação.
/home/flyerpc/.config
informações de versões, dependências ...
as informações dessa pasta é puxada com esse comando: pacman -Ql
/var/lib/pacman/local
Local que armazena miniaturas de imagens
/home/flyerpc/.cache/thumbnails
temas para seu computador em [url=https://wiki.archlinux.org/title/GTK_(Portugu%C3%AAs)]GTK[/url]
/usr/share/themes
Papeis de paredes do Xfce(11,2 MiB )
/usr/share/backgrounds/xfce
configuração do menu iniciar
/usr/share/desktop-directories
Barra de aplicações
/home/flyerpc/.local/share/applications/
Aplicações básicas do usuário, se arrasta-los para a dock cria um atalho
/usr/share/applications
log de notificações do Xfce
/home/flyerpc/.cache/xfce4/notifyd
Letras / fontes
/usr/share/fonts
Ícones
/usr/share/icons
Recursos compartilhados entre vários pacotes, como documentação,
man pages, informações de fuso horário, fontes e outros recursos.
/usr/share
[AUR] scripts do RUA/AUR baixados e aguardando para serem compilados (pode deletar)
Etapa 1, diretório em que os pacotes AUR são clonados.
/home/flyerpc/.config/rua/pkg
[AUR] RUA = arquivos compilados (pode deletar)
Etapa 2, os pacotes revisados são copiados aqui e, em seguida, construídos
/home/flyerpc/.cache/rua/build
[AUR] RUA = pronto para instalar (pacman -U) (pode deletar)
/home/flyerpc/.local/share/rua/checked_tars/
Ótimo local para se criar uma Lixeira
/home/flyerpc/.local/share/Trash/files
ou
trash:///
Bootloader do sistema
/boot/grub
/usr/lib/grub
/usr/share/grub
para configurar o grub, edite esse arquivo.
nano /etc/default/grub
PASTAS DE JOGOS/SOFTWARES
----------------------------------------------------------------------
- Código:
TOX Mensageiro P2P (pacman -S toxic) localidade do profile local.
/home/flyerpc/.config/tox/toxic_profile.tox
Gerenciador de senhas (pacman -S keepass)
/usr/share/keepass/Languages
pitivi editor de vídeo
/home/flyerpc/.local/share/pitivi
persepolis (download do youtube)
/home/flyerpc/.persepolis
download de vídeos inacabados, ficam na pasta /proc
----------------------------------------------------------------------
Jogos
----------------------------------------------------------------------
Para ler relatórios de erro em jogos feitos em unity. (escolha a pasta do jogo) Player.log
/home/flyerpc/.config/unity3d
winetricks
/home/flyerpc/.local/share/wineprefixes
onde todos os programas instalados com winetricks ficam
/home/flyerpc/.cache/winetricks
onde fica os atalhos de jogos instalado com wine
/home/flyerpc/.local/share/desktop-directories
arquivos do próprio wine como: gecko mono
/usr/share/wine
----------------------------------------------------------------------
GOG
----------------------------------------------------------------------
Heroic games (quando se instala a GoG pela Heroic)
GOG - pasta temporária antes de transferir os arquivos para o local final
/home/flyerpc/.cache/heroicGOGdl
Stardew Valley - GoG
/home/flyerpc/.config/StardewValley/Saves
Stardew Valley - fotos
/home/flyerpc/.local/share/StardewValley/Screenshots
Fell Seal: Arbiter's Mark - GoG
/home/flyerpc/Fell Seal/saves/
Adicionar fotos no jogo
/home/flyerpc/Fell Seal/customdata/portraits
Nebuchadnezzar - GoG (mods) (screenshots)
/home/flyerpc/.local/share/NeposGames/Nebuchadnezzar/save
Divinity Original Sin - GoG
/home/flyerpc/Larian Studios/Divinity Original Sin Enhanced Edition/PlayerProfiles
Pillars of Eternity - GoG
/home/flyerpc/.local/share/PillarsOfEternity/SavedGames
Neverwinter Nights - GoG
/home/flyerpc/.local/share/Neverwinter Nights/saves
democracy 3 - GoG (screenshots) (mods)
/home/flyerpc/.local/share/democracy3/savegames
Baldur's Gate - GoG
save + portraits
/home/flyerpc/.local/share/Baldur's Gate - Enhanced Edition
Baldur's Gate II - GoG
/home/flyerpc/.local/share/Baldur's Gate II - Enhanced Edition
witcher 2 - GoG
/home/flyerpc/.local/share/cdprojektred/witcher2/GameDocuments/Witcher 2/gamesaves
Tyranny - GoG
/home/flyerpc/.local/share/Tyranny/SavedGames
Train Fever - GoG
/home/flyerpc/.local/share/Train Fever/save
Beholder - GoG
/home/flyerpc/Warm Lamp Games/Beholder/Saves
pulstar - GoG
/home/flyerpc/.local/share/SNK/pulstar
The King of Fighters 2002 - GoG
/home/flyerpc/.local/share/SNK/kof2k2nd
Ascendant - GoG (screenshots vem parar nessa pasta)
/home/flyerpc/.config/unity3d/Hapa Games/Ascendant
Sid Meier's Civilization IV: The Complete - GoG (wine)
/home/flyerpc/Documentos/My Games/Civ4/Saves/single
outros locais
/media/flyerpc/DRMFREE/wine/CivilizationIV/wine/drive_c/users/flyerpc/AppData/Local/My Games/Civ4
/media/flyerpc/DRMFREE/wine/CivilizationIV/wine/drive_c/users/flyerpc/Saved Games
local de mods
/home/flyerpc/Documentos/My Games/Civ4/MODS
/home/flyerpc/Documentos/My Games/Civ4/ScreenShots
DinsCurse - DepthsOfPeril - DinsLegacy - Zombasite - GoG
/home/flyerpc/.local
Pastas correspondentes ao nome do jogos,
o arquivos user.cfg quando editado é possível mudar os parâmetros do jogo.
Zomboid - GoG
isso não deveria estar aqui
/proc/1954/task/1954/cwd/Zomboid
Gurumin: A Monstrous Adventure - GoG (wine)
/media/flyerpc/DRMFREE/wine/gurumim/exe/drive_c/users/flyerpc/Application Data/FALCOM/GURUMIN
Fallout3 - GoG (wine)
/home/flyerpc/Documentos/My Games/Fallout3/Saves
The Elder Scrolls IV Oblivion - GoG (wine)
/home/flyerpc/Documentos/My Games/Oblivion
----------------------------------------------------------------------
STEAM
----------------------------------------------------------------------
LOCALIZAÇÃO DOS JOGOS INSTALADOS pela steam
pasta padrão
/media/flyerpc/Steam/steamapps/common
local de instalação dos proton
/home/flyerpc/.local/share/Steam/steamapps/common
Local de vários saves em nuvem
/home/flyerpc/.local/share/Steam/userdata/1150652640
Grim Dawn
/home/flyerpc/.local/share/Steam/userdata/1150652640/219990/remote/save/main
Grim Dawn options keybindings
/media/flyerpc/SteamLibrary/steamapps/compatdata/219990/pfx/drive_c/users/steamuser/Documents/My Games/Grim Dawn/
long dark
/home/flyerpc/.local/share/Steam/userdata/1150652640/760/remote/305620
Europa 4 universalis
/home/flyerpc/.local/share/Steam/userdata/1150652640/760/remote/236850
Dawn of War (ScreenShots)
/home/flyerpc/.local/share/Steam/steamapps/common
Titan Quest
/home/flyerpc/.local/share/Steam/steamapps/compatdata/475150/pfx/drive_c/users/steamuser/My Documents/My Games/Titan Quest - Immortal Throne/SaveData
HotlineMiami2 (mods)
/home/flyerpc/.local/share/HotlineMiami2
Terraria
/home/flyerpc/.local/share/Terraria
Oxygen Not Included
save offline
/home/flyerpc/.config/unity3d/Klei/Oxygen Not Included/save_files
save na nuvem
/home/flyerpc/.config/unity3d/Klei/Oxygen Not Included/cloud_save_files
----------------------------------------------------------------------
EPIC
----------------------------------------------------------------------
pasta padrão que fica muitos save game e também programas.
/home/flyerpc/.local/share
Civilization 6
/home/flyerpc/.local/share/aspyr-media/Sid Meier's Civilization VI/Saves/Single/
mod
/media/flyerpc/SteamLibrary/steamapps/common/Sid Meier's Civilization VI/steamassets/base/assets
Don't Starve
/home/flyerpc/.steam/steam/userdata/1150652640/219740/
Cities Skylines
/home/flyerpc/.local/share/Colossal Order/Cities_Skylines/Saves/
Tropico 6
/home/flyerpc/.local/share/Tropico6/Saved/SaveGames/
Worms Reloaded
/home/flyerpc/.local/share/Team17 (FALTA CONFIRMAR)
ou
/home/flyerpc/.local/share/Steam/userdata/1150652640/22600/remote/home/flyerpc/.local/share/Team17
SimCity 2013 executável
/home/flyerpc/Games/simcity-2013/drive_c/Program Files (x86)/Origin/Origin.exe
SimCity 2013 local dos games da origin
/home/flyerpc/Games/simcity-2013/drive_c/users/flyerpc/Meus Documentos/SimCity/Games/
Observação: dentro dessa pasta contém uma subpasta para cada save!
SimCity 2013 como são as pastas com saves
9a3b67ca9f02c197
SimCity 2013 pirata
/home/flyerpc/Games/simcity-2013/drive_c/Program Files (x86)/install/SimCity/SimCity.exe
SimCity 2013 Save pirata
9a3b6720a2b84853
Diablo 1 devilutionx
informações de inicialização do game
/home/flyerpc/.local/share/diasurgical/devilution
instalação
/home/flyerpc/.cache/rua/build/devilutionx
local que cola os arquivos .MPQ retirados do .EXE
/usr/share/diasurgical/devilutionx
traduções
/home/flyerpc/.cache/rua/build/devilutionx/src/devilutionX-1.3.0/Translations
The Bard's Tale
/home/flyerpc/.local/share/BardTale/data/SavedGames
----------------------------------------------------------------------
LUTRIS
----------------------------------------------------------------------
Local que ficam instalado os jogos das lojas, se feito pelo Lutris
Lutris capas para jogos
/home/flyerpc/.local/share/lutris/banners
Lutris prefix
/home/flyerpc/.local/share/lutris/runners
EPIC
/media/flyerpc/Lutris/Epic Games/drive_c/Program Files/Epic Games
BATTLE.NET
/media/flyerpc/Lutris/Battle.net/drive_c/Program Files (x86)
ORIGIN
/media/flyerpc/Lutris/Origin/Simcity/drive_c/Program Files (x86)/Origin Games/
Ubisoft
/media/flyerpc/Lutris/Ubisoft/drive_c/Program Files (x86)/Ubisoft/Ubisoft Game Launcher/games
GOG Galaxy
/media/flyerpc/Lutris/GOG/GOG Galaxy/APP LUTIS/drive_c/Program Files (x86)/GOG Galaxy/Games
faça uma pasta para cada jogo.
----------------------------------------------------------------------
Jogos nativos de linux
----------------------------------------------------------------------
0ad
/home/flyerpc/.local/share/0ad/saves
flare (mods)
/home/flyerpc/.local/share/flare
----------------------------------------------------------------------
Jogos do emulador (Fightcade)
----------------------------------------------------------------------
Fightcade (local da maioria das roms)
/home/flyerpc/.fightcade2/emulator/fbneo/ROMs
roms do video-game snes9x "super nintendo"
/home/flyerpc/.fightcade2/emulator/snes9x/ROMs
roms do video-game FBNeo "MegaDrive"
/home/flyerpc/.fightcade2/emulator/fbneo/ROMs/megadrive
não usar está pasta para guardar roms
/home/flyerpc/.fightcade2/ROMs
Como pesquisar a localização de um programa:
$ which -a firefox
$ pacman -Ql firefox
"which" ou "pacman -Ql" dará informações da localização para binários executáveis.
Enquanto o comando "ls -lh" te mostrará informações da pasta.
$ ls -lh /usr/bin/firefox
 VOLTAR AO TOPO VOLTAR AO ÍNDICE
VOLTAR AO TOPO VOLTAR AO ÍNDICEÚltima edição por ADRIANNO em Seg 22 Abr 2024, 9:24 am, editado 20 vez(es)
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:28 pm
por ADRIANNO Ter 07 Nov 2023, 1:28 pm
Última edição por ADRIANNO em Qua 15 Nov 2023, 4:43 pm, editado 1 vez(es)
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:28 pm
por ADRIANNO Ter 07 Nov 2023, 1:28 pm
Última edição por ADRIANNO em Qua 15 Nov 2023, 4:43 pm, editado 3 vez(es)
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:28 pm
por ADRIANNO Ter 07 Nov 2023, 1:28 pm
VOLTAR AO ÍNDICE PRÓXIMA PÁGINANão é necessário reter todos esses comandos em sua memória, pois eles estão prontamente acessíveis em livros e em guias como esse. O efetivo mérito de uma instrução de cunho técnico não reside na memorização de informações, mas sim na capacidade de treinar a mente para aplicar uma análise lógica na utilização dessas informações, com o objetivo de resolver o desafio em questão.

Fonte da imagem > https://wiki.archlinux.org/title/core_utilities
O site https://explainshell.com é uma ferramenta online que permite entender facilmente o funcionamento de comandos da linha de comando do Linux e do Unix.
Ele ajuda os usuários a desmembrar comandos complexos, fornecendo explicações detalhadas para cada argumento e opção usados no comando.
Vou te familiarizar com os comandos básicos de um sistema POSIX (Portable Operating System Interface)
Há um conjunto de utilitários essenciais no sistema GNU/Linux, os quais são ferramentas fundamentais e básicas para o correto funcionamento do sistema.
Essas ferramentas são tradicionais do Unix, sendo que muitas delas foram padronizadas pelo POSIX e permanecem em constante desenvolvimento, sendo amplamente utilizadas até os dias de hoje.
A POSIX define um conjunto unificado de padrões para manter a compatibilidade entre todos os sistemas operacionais do tipo Unix-like,
sendo o Linux um exemplo, essa padronização possibilita o compartilhamento de ferramentas entre essa família,
isso permite que você troque de distribuição Linux sem que se perceba grandes discrepâncias.
Em outras palavras, a aderência aos padrões POSIX suaviza a transição entre diferentes ambientes Linux, criando uma experiência mais contínua os usuários.
As diferenças entre diferentes distribuições Linux costumam se concentrar em nuances sutis relacionadas à filosofia e ao foco de cada uma, abordando aspectos como privacidade, simplicidade, uso em servidores, usuário-friendly, offline, científico, elegante, otimizado, entre outros.
Esses ajustes finos estão incorporados nos seguintes aspectos: "Gerenciadores de Pacotes", "Estrutura de Diretórios", "Dependências", "Formatos de Pacotes", "Métodos de Inicialização", "Políticas de Atualização" e "Seleção de Software Padrão".
Aqui temos quatro exemplo de utilitários que fazem parte do sistema operacional Linux:
ls (listar arquivos), cp (copiar arquivos), mv (mover arquivos), rm (remover arquivos) entre muitos outros utilitários de linha de comando.
Esses comandos vêm acompanhados de instruções que fornecem informações adicionais sobre como o comando deve se comportar, é uma combinação de letras e números.
Possibilitando redirecionar uma entrada para produzir saídas. (conhecido como E/S ou I/O em inglês).
Além disso, é possível estabelecer uma interconexão entre comandos utilizando pipes, simbolizado por esse caractere vertical |
Os pipes têm a capacidade de direcionar a saída de um comando para servir como entrada para outro comando subsequente, estabelecendo uma conexão contínua.
Uma ampla variedade de tarefas relacionadas à manipulação de arquivos e texto usam essa abordagem, atendendo tanto aos usuários comuns quanto a cientistas de dados.
Após uma breve introdução aos complementos dos comandos, finalmente, apresentarei os comandos (programas binários) concebidos para funcionar via linha de comando.
Esses programas estão integrados ao ambiente GNU/Linux e seus códigos-fonte são acessíveis.
Por serem gratuitos, você também os encontra em versões com interfaces gráficas compondo outras ferramentas.
Embora o Linux ofereça interfaces gráficas de usuário (GUI), o uso de comandos na linha de comando (CLI) pode ser mais eficiente para várias tarefas, mesmo para iniciantes.
Com base nas premissas apresentadas, irei expandir essa introdução:
Observações:
¹ Saída é o termo usado para se referir às informações ou resultados que aparecem na tela após a execução de um comando.
Esses resultados podem variar de um simples texto exibido na tela a uma lista de arquivos ou diretórios, informações de status, mensagens de erro ou até mesmo resultados processados ou filtrados. Você também tem a opção de redirecionar essa saída para um arquivo, permitindo que ela seja armazenada em um documento.
Quando alguém solicitar que você imprima a saída de um comando, essa pessoa espera ver esses resultados na tela do terminal.
A habilidade de capturar e manipular a saída dos comandos é essencial para trabalhar de forma eficaz no ambiente Linux.
² Os comandos podem variar dependendo do shell utilizado: Bash Zsh Fish
³ Todos os comandos possuem argumentos, opções e parâmetros, e são sensíveis a maiúsculas e minúsculas.
Cada comando possui seus próprios argumentos de linha de comando. Por exemplo:
-a, --all
-l, --list
-o, --out
-q, --quiet
-i, --interactive (Solicita confirmação do usuário s/n)
-r, -R, --recursive: opera recursivamente (desce na árvore de diretórios).
-v, --verbose: exibe informações adicionais na saída padrão ou de erro.
No entanto, em alguns comandos específicos, é possível notar novos significados para esses argumentos:
Um exemplo disso é a opção -f, a qual possui dois significados distintos quando utilizada em programas diferentes.
Em tar e gawk: -f, --file: especifica o nome do arquivo.
Em cp, mv, rm: -f, --force: força a execução da ação.
Teclas de atalho que o Linux reconhece:
Ctrl + C = Interrompe um programa, finaliza o processo atual.
Ctrl + Z = Pausa um programa, coloca o processo em segundo plano; fg (foreground) volta com o processo.
- Ctrl + Z informações:
- Os comandos suspensos são numerados para que você possa trazer de volta apenas os que desejar, usando:
fg 1
fg 2
fg 3
Se preferir evitar abrir o processo para encerrá-lo com Ctrl + C, há outra maneira de fazê-lo:
Encerrando os processos em segundo plano utilizando o comando kill seguido pelo número do trabalho (PID).


Ctrl + E = Move o cursor para o final da linha.
Ctrl + K = Apaga tudo da posição atual do cursor até o final da linha.
Ctrl + U = Apaga tudo da posição atual do cursor até o início da linha.
Ctrl + Y = Restaura o texto apagado pelas teclas Ctrl + K ou Ctrl + U.
Ctrl + W = Apaga a palavra à esquerda do cursor.
Ctrl + Shift + C = Para copiar o texto selecionado.
Ctrl + Shift + V = Para colar o texto.
Ctrl + L = Limpa o terminal "clear".
Ctrl + R = Realiza uma pesquisa nos comandos anteriores, insira uma palavras-chave depois; pressione repetidamente Ctrl + R para alternar entre os comandos encontrados.
Ctrl + T = Inverte de posição os dois caracteres à esquerda do cursor.
Ctrl + Seta para a Direita = ou para esquerda,move o cursor para a próxima palavra; o fim de uma palavra é determinado por !@#$%¨&*()_+{}?:><[]=-,.'".
Shift + Seta para cima = ou para baixo, rola o texto; funciona no terminal do XFCE.
Shift + Tab = Em alguns programas de terminal (TUI) com guias ou abas, permite que você mude o foco para a guia anterior.
Ctrl + D = Fecha o terminal, ou encerrará qualquer comando em execução, se houver.
Não existe um comando específico para desfazer uma ação no terminal, como recuperar um texto que tenha sido apagado.
Essa função comum em editores de texto não se aplicam no terminal, mas o shell interativo oferece um histórico de comandos; Ctrl + R.
Uma tarefa comum ao utilizar o terminal é obter o caminho completo de um arquivo com o qual você deseja trabalhar. Existem várias maneiras de obter esse caminho, incluindo:
Vamos obter o caminho do arquivo random_alert.py, supondo que seu arquivo esteja no diretório de trabalho:
[adr1@netlinux Documentos]$ realpath random_alert.py
resultado do comando:
'/home/adr1/Documentos/random_alert.py'
mais pela frente você aprenderá a usar o comando cd para mudar de diretório.
Outra maneira de obter o caminho completo do arquivo é arrastando-o para a janela do terminal:

O diretório home é o diretório pessoal dos usuários de sistemas Linux. Cada usuário criado nesse Linux tem seu próprio diretório home com suas configurações pessoais.
Você pode referenciar o diretório home de várias maneiras.
Nesse exemplo vou criar 4 pastas no diretório home, usando diferentes formas:

O resultado foi 4 pastas criadas dentro do diretório home:
/home/usuario/media
/home/usuario/media2
/home/usuario/media3
/home/usuario/media4

Se o diretório home for o seu diretório de trabalho atual, faça referência direta aos arquivos existentes pelo nome, sem a necessidade de especificar um caminho completo.
O ponto . também é usado como um indicador para o diretório atual.
media
O caractere til ~ é uma forma comum de referenciar o diretório home.
~/media
Para navegar para o diretório pessoal do usuário:
cd ~
A variável de ambiente $HOME contém o caminho para o diretório home do usuário atual.
$HOME/media
Quando você está em um diretório diferente e precisa especificar um caminho para outro diretório, é importante usar o caminho completo.
Especificar o caminho completo ajuda a evitar erros acidentais, especialmente ao usar comandos destrutivos como rm (para excluir arquivos) ou mv (para mover arquivos).
Observe que há pastas com nomes semelhantes em hierarquias de localização distintas:
/media
/home/usuario/media
/home/usuario/Desktop/media
Em alguns Linux, o diretório /media é usado para montar dispositivos removíveis, como unidades USB, discos rígidos externos, CD-ROMs, DVDs etc.
Atente-se a esses dois comandos e observe o diretório que estão sendo referenciados:
rm ./media
rm /.media
Ambos são comandos usados para deletar arquivos.
O comando rm ./media tem o caminho começando com . e faz referência a nossa home, onde encontramos uma pasta chamada media.
Já neste comando rm /.media o caminho começa com / indicando à raiz do sistema, onde existe uma pasta chamada .media.
O impacto desses dois comandos é consideravelmente diferente. Ao executar o comando que referencia o diretório raiz do sistema, rm /.media,
você precisa obrigatoriamente usar sudo, pois apenas o administrador do computador tem acesso a esses arquivos.
Em contrapartida, não há impactos em deletar uma pasta chamada ./media em sua home, pois se trata de um diretório pessoal,
e qualquer dano causado afetaria apenas os arquivos e pastas relacionados à sua conta de usuário, sem impactar o sistema como um todo.
No terminal, se você estiver em dúvida sobre se está logado como administrador ou usuário comum, basta dar uma olhada no seu prompt de comando, que se parece com isto:
[flyer@netlinux ~]$
ou
[root@netlinux /]#
Esse prompt oferece várias informações importantes. O flyer é o nome do seu usuário,
e netlinux é o nome do host, que corresponde ao conteúdo do arquivo /etc/hostname e é usado para identificar o sistema na rede ou localmente.
Imediatamente após o netlinux, você vê o símbolo ~, que representa o diretório atual, nesse exemplo está no diretório pessoal do usuário.
No segundo prompt, o caractere / indica que você está no diretório raiz do sistema. O diretório raiz é o ponto de partida do sistema de arquivos, e a partir dele, a estrutura de diretórios se ramifica. Quando você vê o / no prompt, isso sinaliza que você está operando no nível mais alto do sistema de arquivos.
Outro aspecto importante desses prompts são os símbolos $ e #, que denotam o tipo de usuário atual e o nível de privilégios que ele possui.
O símbolo $ (cifrão) é usado para usuários comuns, indicando que eles não têm privilégios administrativos.
O símbolo # (sustenido ou cerquilha) é reservado para o superusuário, comumente conhecido como root.
O superusuário tem privilégios administrativos completos, o que inclui realizar tarefas críticas como instalar e remover software do sistema.
O que define essa configuração de prompt (shell prompt) é essa variável PS1 é usada para personalizar essa aparência.
você pode consulta-la, usando o comando:
echo $PS1
[flyer@netlinux ~]$ echo $PS1
[\u@\h \W]\$
\u é substituído pelo nome de usuário atual (neste caso, flyer).
\h é substituído pelo nome do host (neste caso, netlinux).
\W é substituído pelo diretório de trabalho atual (por exemplo, ~ para o diretório home).
\$ representa o tipo de usuário logado, $ para comum, # para root.
Para acessar a conta de usuário root enquanto você está logado como um usuário comum, você pode usar o comando:
su
será solicitado a inserir a senha do usuário root.
****
Após digitar a senha correta, você estará logado como root com privilégios administrativos completos.
Para sair do root, digite:
exit
Em muitas distribuições Linux, a conta root fica desativada, e em vez disso, você deve usar o comando sudo para conceder temporariamente privilégios administrativos.
Operador Lógico
VAMOS CONHECER ALGUNS OPERADORES DE REDIRECIONAMENTO, VOCÊ VERÁ ELES ACOMPANHANDO OS COMANDOS:
> É um sinal de redirecionamento que direciona a saída padrão de um comando para um arquivo, substituindo o conteúdo existente, se houver.
>> Também é um sinal de redirecionamento, mas ao contrário de ">", adiciona a saída padrão de um comando ao final de um arquivo existente, sem substituí-lo.
< Sinal de redirecionamento que utiliza um arquivo como entrada padrão de um comando. O conteúdo do arquivo é usado como entrada para o comando.
<< Sinal de redirecionamento. É útil para inserir texto diretamente no terminal como entrada de um comando.
2> Redirecionar a saída de erro, ele substituirá o conteúdo existente no arquivo de destino.
2>> Adicionará a saída de erro do comando, ao final de um arquivo existente. ls /diretório_inexistente 2>> erro.txt
& Executa o comando em segundo plano, quando colocado no final de um comando você cria uma tarefa em segundo plano.
&& Ele permite que o segundo comando seja executado na mesma linha em conjunto com outros, somente se o primeiro comando for bem-sucedido.
| Símbolo conhecido como "pipe" que permite redirecionar a saída do comando anterior para o próximo comando.
Para quem quer se aprofundar nesses condutores(redirecionadores), pesquise externamente:
stdin (Standard Input): É a entrada padrão de um programa no Linux. Representa o fluxo de entrada de dados, como o teclado ou qualquer outro dispositivo que forneça dados para o programa. É identificado pelo número 0.
stdout (Standard Output): É a saída padrão de um programa no Linux em condições normais. Representa o fluxo de saída de dados, que é exibido no terminal, impressora, arquivo ou outro dispositivo. É identificado pelo número 1.
stderr (Standard Error): É a saída de erro de um programa no Linux, utilizada para exibir mensagens de erro ou informações sobre falhas durante a execução. Também pode ser redirecionada para o terminal, arquivo ou outro dispositivo. É identificado pelo número 2.
tty Abreviação de "Teletype", é um dispositivo de terminal no Linux. Representa um terminal real ao qual um usuário está conectado, seja por meio do console físico ou de terminais virtuais.
pts (Pseudo-Terminal): Representa um terminal emulado por um programa, como o SSH. É usado quando um programa é executado através de uma conexão remota e está associado a um terminal falso.
Conheça alguns termos comumente usados no contexto do shell do Linux.
O que são os Comandos do Linux?
São as instruções que você dá ao shell para executar uma determinada ação.
Realizando todo tipo tarefas diferentes, como abrir um arquivo, criar uma pasta, ou executar um programa.
O que é Shell Scripting?
é como contar uma história para o computador, mas usando uma linguagem de programação.
Em vez de dar apenas um comando de cada vez, você coloca vários comandos juntos escritos em um arquivo de texto, como se fosse uma lista de tarefas.
Você salva esse arquivo na extensão .sh, assim meu_script.sh.
Quando você executa esse arquivo, o computador lê cada comando na ordem em que estão listados e os executa um por um. É uma maneira de dizer ao computador exatamente o que você quer que ele faça.
Com shell scripting, você pode automatizar tarefas repetitivas ou complexas e usando todas as funcionalidade do seu sistema operacional Linux, como variáveis, loops, condicionais...
O que são as Variáveis?
Variáveis são como etiquetas que você cola em coisas para se lembrar delas mais tarde.
No shell, você pode usar variáveis para guardar informações importantes, como palavras, números ou até mesmo nomes de arquivos.
Por exemplo, se você quer se lembrar da frase "abcd_efgh", você pode criar uma variável chamada "var" e colar essa frase nela.
Por exemplo, vamos criar essa variável:
var="echo abcd_efgh"
Para visualizar a variável criada:
$var
Então, sempre que você quiser ver o que está escrito na variável, você pode simplesmente pedir para o computador mostrar para você usando o comando $var.
É como ter post-its virtuais para lembrar as coisas importantes!
O que é uma String?
As strings são usadas para armazenar texto ou dados, podendo ser letras, números, símbolos e espaços vazios, que formam um texto. Por exemplo, "Olá mundo!" é uma string.
Strings são simplesmente dados textuais sem nenhum padrão especial associado a eles. Elas são tratadas de forma literal pelo shell.
Elas podem ser utilizadas em uma variedade de situações, como manipulação de arquivos de texto, processamento de dados e muito mais.
Suponha que você queira armazenar o seu nome em uma string e depois exibi-lo na tela:
Criaremos uma variável chamada "nome" e atribui a ela a string "João".
nome="João"
Agora exibimos ela:
echo "Olá, $nome!"
O que é uma Expressão Regular?
As expressões regulares (também chamadas de regex) são padrões de texto utilizados para encontrar sequências específicas de caracteres em uma string.
Você pode pensar nelas como padrões de busca que você cria para encontrar palavras ou frases específicas em uma grande quantidade de texto.
Por exemplo, se você quer encontrar todas as palavras que começam com "b" e terminam com "la", você pode usar uma expressão regular como:
b.la, onde o . representa qualquer letra única.
Isso fará com que o computador procure por padrões que se encaixem nesse molde e retorne os resultados correspondentes.
O que é Funções?
Permitem que você agrupe um conjunto de comandos para serem executados juntos. Elas são úteis para reutilização de código e organização.
São como receitas que você cria para fazer algo específico. Você pode juntar um monte de passos em uma função e, sempre que precisar fazer essa tarefa, basta chamar a função.
É como ter um conjunto de instruções prontas para uso.
O que é Array?
São estruturas de dados que permitem armazenar múltiplos valores em uma única variável. No shell, os arrays são úteis para manipulação de conjuntos de dados.
O que é Heredoc?
É uma forma de redirecionamento que permite que você forneça entradas de texto para comandos em scripts do shell.
O que é Expansão de Parâmetro?
Serve para extrair uma parte do conteúdo de algo, esse algo podendo ser um strings ou uma variáveis, fazendo a manipulação de seu conteúdo.
Isso permite realizar uma variedade maior de operações de processamento de texto.
Por exemplo, vamos criar um variável:
var="abcd_efgh"
Vamos visualizar parte do conteúdo dessa variável recém criada:
echo ${var#abcd_}
Ficando assim:
efgh
O que é Substituição de Comando?
Permite que você execute um comando dentro de outro comando e use o resultado desse primeiro comando como parte do segundo comando.
substituição de comando com crase (`command`)
substituição de comando com parênteses $(command)
exemplo:
[flyer@linux ~]$ echo A data de hoje é: $(date)
A data de hoje é: dom 07 abr 2024 11:59:02 -03
O que são as condicionais?
São usados para criar script em shell pois controlam o fluxo dos comandos para permitir executar determinadas partes do código com base em uma condição específica.
Avalia algo como verdadeiro ou falso. É uma combinação de testes ou operadores de comparação para se chegar num resultado.
Esses operadores são utilizados nas condicionais para tomar decisões com base em informações sobre arquivos ou variáveis.
No shell do Linux, as condicionais mais comuns são implementadas usando a instrução if.
then: Indica o código que será executado se a condição for verdadeira.
else: Indica o código que será executado se a condição for falsa.
fi: Indica o fim da condicional.
Por exemplo:
Você pode criar um script que verifica se o arquivo.txt existe ou não no diretório atual.
Se o arquivo existir, a mensagem "O arquivo existe." será impressa;
caso contrário, a mensagem "O arquivo não existe." será impressa.
- operadores de comparação:
- Os operadores de comparação são usados para comparar valores numéricos ou alfanuméricos.
Alguns dos operadores de comparação mais comuns incluem:
-eq: Igual a
-ne: Diferente de
-lt: Menor que
-gt: Maior que
-le: Menor ou igual a
-ge: Maior ou igual a
Vamos usar o operador -gt para comparar valores numéricos. Por exemplo, [ 10 -gt 5 ] seria verdadeiro porque 10 é maior que 5.
Além disso, existem operadores de teste que podem ser usados para verificar atributos de arquivos ou variáveis.
Alguns dos operadores de teste comuns incluem:
-f: Verifica se o caminho especificado é um arquivo regular.
-d: Verifica se o caminho especificado é um diretório.
-z: Verifica se a string está vazia.
-n: Verifica se a string não está vazia.
-e: Verifica se o caminho especificado existe.
O que são Redirecionamento?
É o processo de direcionar a entrada, saída ou erro de um comando para ou de um arquivo de texto, ou para um outro comando.
O que é Pipes?
É uma forma de conectar a saída de um comando à entrada de outro, permitindo que você encadeie vários comandos juntos.
O que é Globbing?
É um recurso do shell que permite fazer correspondência de padrões em nomes de arquivos.
O que é Operadores de Comparação?
São utilizados para comparar valores em scripts do shell, tais como == para igualdade, != para desigualdade, < para menor que, > para maior que, entre outros.
O que é Loops?
São estruturas de controle de fluxo que permitem que um conjunto de comandos seja repetido várias vezes. Exemplos incluem for, while e until.
O que é Condicional?
São estruturas de controle de fluxo que executam um conjunto de comandos com base em uma condição. Exemplos incluem if, elif e else.
O que é Arquivos de Configuração?
São arquivos usados para configurar o comportamento de aplicativos, serviços e do próprio sistema operacional. Exemplos incluem ~/.bashrc, /etc/profile, /etc/bash.bashrc.
O que é Variáveis de Ambiente?
São variáveis especiais que contêm informações sobre o ambiente de execução do shell. Exemplos incluem PATH, HOME, USER.
O que é Expansão de Caminho?
É um recurso do shell que permite que você expanda padrões de caminho de arquivos. Exemplo: ~/Documents/*.txt.
O que é Subshell?
É um shell temporário criado dentro de um shell principal. Os comandos executados dentro de um subshell são independentes do shell pai e não afetam seu ambiente.
O que são Sinais (Signals)?
É uma forma de notificação que é enviadas para processos pelo kernel para indicar eventos como interrupções, erros ou solicitações do usuário.
Exemplos de sinais incluem SIGINT (gerado quando o usuário pressiona Ctrl+C) e SIGTERM (usado para solicitar a terminação de um processo).
O que são Serviços e Daemons?
São programas que rodam em segundo plano, como o systemd, NetworkManager, OpenSSH, D-Bus, Avahi, Cron ...
Para realizar tarefas básicas de processamento de texto dentro do terminal, vamos compreender alguns padrões do shell.
Delimitadores de comandos
Os delimitadores dizem onde começa e termina uma expressão regular(regex) que por sua vez são textos usados para identificar sequências de caracteres em uma string.
; Ponto e vírgula, usado como um separador de comandos. Permite que vários comandos sejam executados sequencialmente em uma única linha.
' ' Aspas simples, qualquer variável ou comando dentro de aspas simples não será interpretado, e será tratado como texto comum.
" " Aspas duplas, para definir uma cadeia de caracteres (string), onde os caracteres especiais como ! $ tem seu valor literal preservado.
Permitindo que você faça isso: cd "$HOME/pasta família"
É importante observar que o uso de aspas simples ' ' ou duplas " " em torno do caminho de um diretório impede o uso de caracteres curingas.
Isso ocorre porque o shell trata o conteúdo dentro das aspas como uma string literal, fazendo o caracteres curingas perderem seus poderes.
Vai ter casos que será necessário usar um caractere de escape invés de um delimitador.
Nesse exemplo quero usar o * que é um caractere curinga, mas o nome do meu diretório tem espaço em branco:
cd /home/flyer/Vídeos/Nova\ past* a forma errada de fazer isso:
Caracteres curinga(Wildcards)
* Asterisco, corresponde a zero ou mais caracteres em um nome de arquivo. ls *.txt - lista todos os arquivos com extensão .txt
? Ponto de interrogação, corresponde a um único caractere em um nome de arquivo. ls arquivo?.txt - lista todos os arquivos que tenham a palavra "arquivo" seguida de um caractere.
[] Colchetes, para especificar um conjunto de caracteres possíveis. ls arquivo[12].txt - lista os arquivos arquivo1.txt e arquivo2.txt
{} Chaves, para especificar um conjunto de palavras possíveis. ls {*.txt,*.pdf} - lista todos os arquivos com extensão .txt e .pdf
!! Repete o último comando.
Caracteres de escape, são usados para indicar que o próximo caractere tem um significado especial.
\n Representa uma quebra de linha.
\t Representa um tabulador.
\\ Representa uma barra invertida literal.
\" Representa uma aspa dupla literal.
\$ Representa um cifrão literal.
\ Indicar que o espaço que a segue faz parte do nome do diretório ou arquivo, em vez de representar um separador de argumento.

Outros caracteres especiais
~ Til ou Tilde abrevia o caminho que representa o diretório do usuário atual, ls ~/Documentos outra forma de representação ls $HOME/Documentos
Usando variáveis no shell scripting
As variáveis são armazenadas na memória do processo shell em execução. Cada variável tem um nome único e um valor associado a ela.
No que diz respeito ao limite de quantas variáveis o shell pode armazenar, isso geralmente depende da quantidade de memória disponível.
Escreva quantas quiser, quando você substitui uma variável por outra de mesmo nome, a anterior deixa de existir.
Como declaração uma Variável: Primeiro, você declara uma variável atribuindo um valor a ela, como fazer isso?
Em shells Unix e Linux, o sinal de igual = é comum de ser usado para atribuir esse valor.
titulo_da_variavel="teor_da_variavel"
É importante dizer que o título da variável só pode conter letras (a-z, A-Z) e sublinhados _ os caracteres subsequentes podem incluir números (0-9).
Após ter suas variáveis declaradas, acesse os valores armazenados em seus próximos comandos.
Para acessar o valor armazenado na variável, você usa o caractere $ seguido pelo nome da variável.
vou usar o comando echo, seguido pelo título da variável $nome para assim acessar seu conteúdo.

01 Você pode economizar digitação armazenando o caminho do arquivo em uma variável e, em seguida, usando essa variável nos próximos comandos com o operador &&
file_path="$HOME/entrada.txt" grep -c "meu texto" "$file_path" && grep -n "meu texto" "$file_path"
02 Calculando a soma de dois números 897+675:
num1=897 num2=675; soma=$((num1 + num2)); echo "A soma de $num1 e $num2 é igual a $soma"
(minimalista) I=897 II=675; soma=$((I + II)); echo "$soma"
03 Repete o nome dos arquivo ou diretório da sua home com uma mensagem embutida.
diretorio="$HOME/"; for arquivo in "$diretorio"/*; do echo "Processando o arquivo: $arquivo"; done
04 Lendo entrada do usuário e usando como parte de um comando.
echo "Digite seu nome:"; read nome; echo "Olá, $nome! Bem-vindo ao nosso sistema."
Dicas de sites para aprimorar sua compreensão dos comandos Linux: link¹
VOLTAR AO TOPO VOLTAR AO ÍNDICEÚltima edição por ADRIANNO em Dom 07 Abr 2024, 3:49 pm, editado 20 vez(es)
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:29 pm
por ADRIANNO Ter 07 Nov 2023, 1:29 pm
VOLTAR AO ÍNDICE PRÓXIMA PÁGINAProgramar no Linux
Lista de linguagens de programação
Você pode usar o Arch Linux para desenvolver em praticamente todas as linguagens de programação disponíveis.
O terminal do Linux tem todas as ferramenta necessárias para os programadores.
Nesse terminal você cria automações de tarefas, tem acesso rápido a ferramentas para gerenciar servidores remotos.
Falando propriamente do Arch Linux, por ele ser rolling release, você terá acesso rápido às versões mais recentes de software e bibliotecas,
frameworks e outras ferramentas de desenvolvimento, com acesso fácil aos softwares e todo gerenciamento de dependências para seu projeto.
O que é benéfico para desenvolvedores que querem trabalhar com as tecnologias mais recentes.
Como o Linux é de código aberto, os programadores têm acesso ao código-fonte do kernel e de muitas outras partes do sistema operacional.
Isso permite uma compreensão mais profunda do funcionamento interno do sistema e a capacidade de modificar o código para atender às necessidades.
A maioria das linguagens de programação e suas ferramentas estão disponíveis nos repositórios oficiais do Arch Linux.
Podem ser instaladas através do gerenciador de pacotes, Pacman ou AUR (Arch User Repository).
Você pode trabalhar com diversas linguagens, como Python, Ruby, Perl, PHP, Java, JavaScript (Node.js), C/C++, Go, Rust, entre outras.
Além disso, o Arch Linux oferece suporte a uma grande variedade de ambientes de desenvolvimento, IDEs (Integrated Development Environments) e ferramentas de compilação.
Se você já está utilizando o Arch Linux, você pode empregar este comando para buscar por ferramentas de IDE nos repositórios oficiais.
pacman -Ss | grep -i -E 'text|programming|development'
Se você souber o nome da ferramenta que está procurando, torna-se ainda mais fácil:
pacman -Ss nome_aqui
Além das bibliotecas fornecidas pela própria linguagem de programação, é possível aproveitar os programas e bibliotecas instalados no próprio Linux.
Por exemplo, para desenvolver um aplicativo web que requer uma camada adicional de segurança para protegê-lo contra bots.
você pode integrar em seu projeto o programa haskell-recaptcha que está instalado no seu Arch Linux.
O reCAPTCHA é um serviço oferecido pelo Google, e você pode facilmente comunica-lo com seu projeto, independentemente da linguagem de programação escolhida.
Isso pode ser realizado de várias maneiras, incluindo execução externa, criação de wrappers, chamadas diretas ou utilizando a FFI (Foreign Function Interface).
Você pode usar sua linguagem de programação dentro do terminal do Linux.
Algumas linguagens:
Bash: A linguagem de script padrão no terminal Unix-like, usada para automatizar tarefas e interagir com o sistema operacional.
Perl: Outra linguagem de script usada para manipulação de texto e automação de tarefas.
Exemplo de comando: perl script.pl para executar um script Perl chamado script.pl.
Python: Uma linguagem de programação de alto nível usada para uma ampla variedade de tarefas.
Exemplo de comando: python script.py para executar um script Python chamado script.py.
Node.js (JavaScript): Uma plataforma para executar JavaScript do lado do servidor.
Exemplo de comando: node script.js para executar um script JavaScript chamado script.js.
C/C++: Linguagens de programação de propósito geral amplamente usadas.
Exemplo de comando: gcc programa.c -o programa && ./programa para compilar e executar um programa C chamado programa.c.
Ruby: Uma linguagem de programação dinâmica conhecida por sua simplicidade e elegância.
Exemplo de comando: ruby script.rb para executar um script Ruby chamado script.rb.
PHP: Uma linguagem de programação usada principalmente para desenvolvimento web.
Exemplo de comando: php script.php para executar um script PHP chamado script.php.
Java: Uma linguagem de programação popular usada para desenvolver uma ampla variedade de aplicativos.
Exemplo de comando: java Programa para executar um programa Java chamado Programa.
SQL: Linguagem de consulta estruturada usada para interagir com bancos de dados.
Exemplo de comando: mysql -u usuário -p senha -e "SELECT * FROM tabela" para executar uma consulta SQL em um banco de dados MySQL.
HTML/CSS: você pode usar editores de texto como Vim ou Nano para editar. Essas linguagens de marcação e estilo são usadas para criar páginas da web.
Embora não sejam executáveis diretamente no terminal, você pode editá-las usando esses editores de texto. Além disso, você pode usá-las em conjunto com ferramentas como curl para exibir páginas da web no terminal.
Se você pretende trabalhar com HTML, CSS, JavaScript e outras relacionadas ao design web, saiba que existem vários editores disponíveis no Linux.
Um exemplo é o Bluefish, um software de código aberto e gratuito em português.
Você pode usar o Bluefish para editar arquivos de backend, como PHP, Python, Ruby, entre outros, contudo o foco do Bluefish está no desenvolvimento de frontend.
Ele oferece recursos como realce de sintaxe e autocompletar, e pode lidar com vários projetos simultaneamente. Além disso, o Bluefish possui alguns plugins opcionais, como o Gucharmap, Intltool, necessário para compilar softwares. Manual | Wiki
você pode programar no Linux para criar aplicativos destinados a plataformas como Windows e mobile.
Desenvolvimento de Aplicativos para Windows:
Você pode usar ferramentas de cross-compilação para compilar aplicativos do Windows diretamente no Linux.
Por exemplo, você pode usar o MinGW (Minimalist GNU for Windows) para compilar programas C/C++ para Windows em um ambiente Linux.
Muitas plataformas de desenvolvimento, como .NET Core e Electron, oferecem suporte para desenvolvimento multiplataforma, permitindo que você escreva código em Linux e compile para Windows.
Desenvolvimento de Aplicativos para Mobile:
O desenvolvimento de aplicativos Android pode ser feito no Linux usando o Android Studio, que é uma IDE oficial fornecida pelo Google.
Uma forma open source de programar para Android sem depender das ferramentas oficiais do Google
é usando o projeto F-Droid em conjunto com ferramentas de desenvolvimento de código aberto.
Você pode usar o F-Droid para distribuir seus aplicativos Android de código aberto e também para descobrir e baixar outros aplicativos de código aberto para Android.
Gradle é uma ferramenta de compilação para construir aplicativos Android. Ele é de código aberto e você pode configurá-lo para compilar e empacotar seus aplicativos Android.
Embora não seja estritamente de código aberto, Genymotion é uma ferramenta popular de emulação Android que oferece uma versão gratuita para uso pessoal.
Você pode usá-lo para testar e depurar seus aplicativos Android no Linux.
Frameworks como Flutter (para desenvolvimento de aplicativos nativos) e React Native (para desenvolvimento de aplicativos multiplataforma) oferecem suporte ao desenvolvimento no Linux.
Para o desenvolvimento iOS, você pode configurar um ambiente de compilação remota em um Mac e usar ferramentas como SSH para se conectar e compilar seu código a partir do Linux.
Tipos de Linguagens
Compilador/Interpretador
Algumas linguagens de programação requerem um compilador para construir um aplicativo executável do código-fonte, enquanto outras usam um interpretador.
As linguagens interpretadas, o código-fonte é lido linha por linha e executado imediatamente pelo interpretador.
Para utilizar a interpretação, você escreve seu código na sintaxe da linguagem desejada utilizando um editor de texto, e então solicita ao interpretador que execute seu código como um script.
Por exemplo, se estiver trabalhando com Python, uma linguagem interpretada, você pode executar um script chamado meu_script.py utilizando o interpretador Python com o seguinte comando:
python meu_script.py
Aqui, python é o nome do interpretador Python.
Outras linguagens interpretadas, como Perl, Ruby e JavaScript, também possuem seus próprios interpretadores que podem ser chamados de maneira semelhante.
Para adquirir o básico necessário para utilizar uma linguagem de programação, é suficiente instalar o compilador ou o interpretador
Abaixo vou listar alguns dos interpretadores mais renomados disponíveis nos repositórios do Arch Linux para instalação:
Interpretação de código Python. sudo pacman -S python para pesquisar complementos pacman -Ss python
Interpretação de código Ruby. sudo pacman -S ruby para pesquisar complementos pacman -Ss ruby
Interpretação de código PHP. sudo pacman -S php para pesquisar complementos pacman -Ss php
Interpretação de código Perl. sudo pacman -S perl para pesquisar complementos pacman -Ss perl
Interpretação de código Lua. sudo pacman -S lua para pesquisar complementos pacman -Ss lua
Interpretação de código R. sudo pacman -S r para pesquisar complementos pacman -Ss r
Interpretação de código JavaScript usando o ambiente Node.js. sudo pacman -S nodejs para pesquisar complementos pacman -Ss nodejs
Esses complementos pode ser bibliotecas ou frameworks, pois dependendo da linguagem, você pode querer estender as funcionalidades da linguagem.
Essas bibliotecas geralmente são instaladas usando o gerenciador de pacotes da linguagem ou do Linux, ou através de sistemas de gerenciamento de pacotes de terceiros, como o python-pipx para Python ou o npm para Node.js.
Bibliotecas e Frameworks
As bibliotecas são conjuntos de funcionalidades que podem ser chamadas individualmente em um projeto, oferecendo controle direto sobre sua utilização.
Por outro lado, um framework pode "dominar" seu código, no sentido de que ele estabelece a estrutura e as convenções que você deve seguir ao desenvolver seu aplicativo.
Você está subordinado às decisões arquiteturais e aos padrões definidos pelo framework, o que pode influenciar significativamente a maneira como você escreve seu código.
Mas o framework simplifica o desenvolvimento.
Compilar linguagens no Linux
Compilar é o processo de transformar código-fonte em um programa executável.
Isso envolve o uso de um compilador, como o GCC (GNU Compiler Collection), que é uma ferramenta que compila uma variedade de linguagens de programação,
incluindo C, C++, Objective-C, Fortran, Ada, Go, D etc.
Python, por outro lado, é uma linguagem interpretada, o que significa que o código Python é executado diretamente pelo interpretador Python, sem a necessidade de compilação prévia para código de máquina. O GCC é usado para compilar somente aquelas linguagens que precisam de compilação.
Para compilar um programa usando o GCC no Linux, é fácil:
Escreva seu código-fonte em um arquivo com a extensão apropriada para a linguagem que você está usando (por exemplo, .c para C, .cpp para C++).
Abra um terminal e navegue até o diretório onde seu arquivo de código-fonte está localizado.
Execute o comando de compilação, fornecendo o nome do arquivo de origem e o nome do arquivo de saída.
Por exemplo, para compilar um programa em C chamado meu_programa.c e gerar um arquivo executável chamado meu_programa, você pode usar o seguinte comando:
gcc meu_programa.c -o meu_programa
Algumas linguagens de programação compiladas dispensam o uso do GCC.
1. Linguagens puramente compiladas, como Rust (com o compilador rustc) e Haskell (utilizando o GHC), possuem suas próprias ferramentas de compilação.
2. Por outro lado, Java opera em uma Máquina Virtual Java (JVM) e é compilado através do seu próprio compilador, o javac.
3. Julia possui um compilador próprio integrado, conhecido como JIT (Just-In-Time). Isso significa que o código Julia é compilado dinamicamente, sob demanda, em tempo de execução.
4. Enquanto o Delphi é uma IDE e uma linguagem de programação de alto nível baseada em Object Pascal, muito usado no Windows.
O Free Pascal é uma linguagem multiplataforma bem mais ampla, sendo uma alternativa ao Delphi para usuários Linux.
A linguagem Free Pascal (FPC) oferece compatibilidade com código escrito em Turbo Pascal 7.0 e Delphi. O Lazarus é sua IDE, semelhante ao Delphi, projetada para Free Pascal. Assim como no Delphi essa linguagem é orientada a objetos, como classes, herança e polimorfismo. Quem já trabalhou com o Delphi, vai continuar tendo o designer de formulários visuais e depurador integrado.
Não importa onde você compile seu código, seja em uma IDE ou usando ferramentas de linha de comando, como o GCC direto do terminal.
Uma vez que seu código é compilado, você pode usar o terminal para executar seu programa e também interagir diretamente com ele, fornecendo entrada e analisando a saída.
Pelo terminal você pode depurar e analisar o seu desempenho, usa-lo dentro de algum scripts etc.
Existem outras ferramentas que podem ser úteis para simplificar o processo de compilação e gerenciamento de projetos maiores, como:
Make: é software livre para automatizar o processo de construção de programas a partir de seus arquivos fonte, reduzindo a necessidade de recompilar todo o programa a cada modificação. Ele utiliza um arquivo chamado makefile para determinar como gerar arquivos executáveis, o Make é específico para a plataforma em que é executado.
CMake: Tanto o CMake quanto o Make são ferramentas de construção de software, mas eles têm abordagens diferentes para compilação.
O CMake oferece uma simplificação na geração de sistemas de compilação para diferentes plataformas, tornando mais fácil para os desenvolvedores.
Ele usa arquivos CMakeLists.txt, que descrevem a estrutura do projeto, invés dos makefile do Make.
- abrir foto:
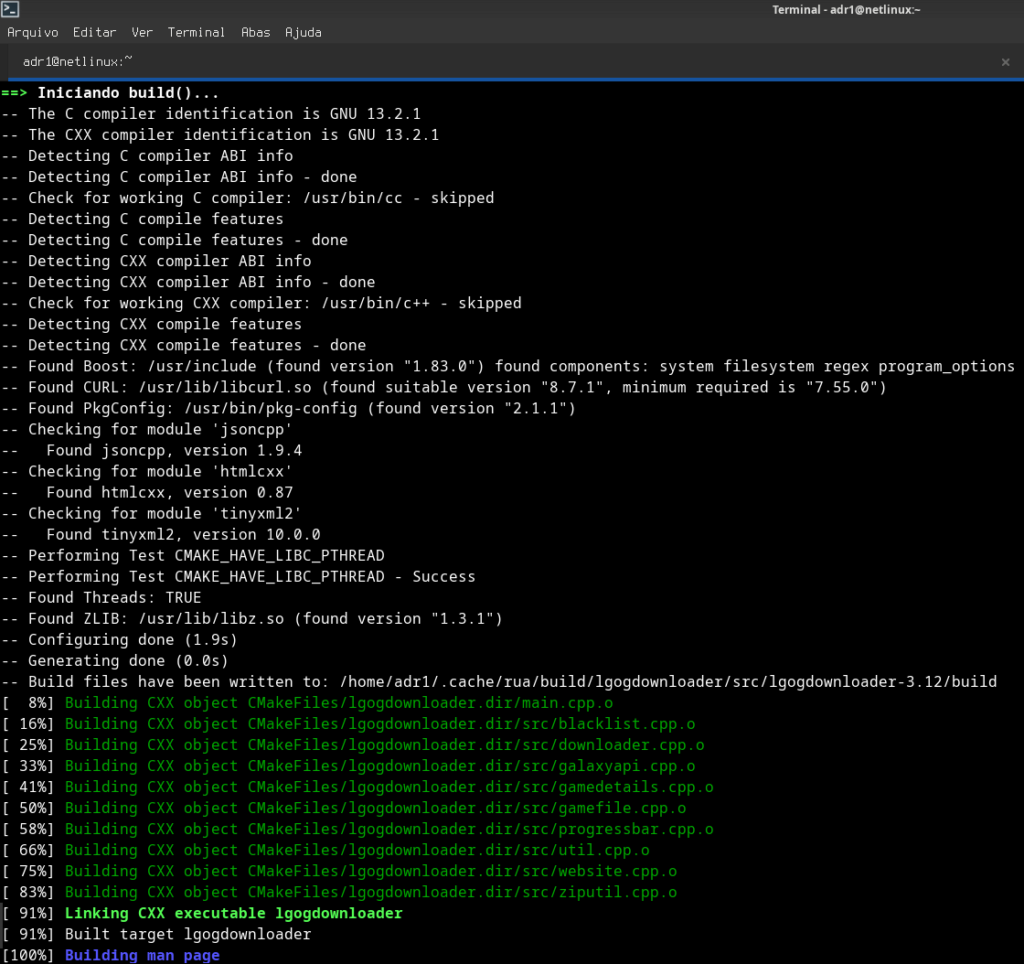

Autotools: Um conjunto de ferramentas (como autoconf, automake e libtool) usadas para criar scripts de configuração e makefiles para projetos de software.
mk-configure: Ele oferece uma alternativa leve e eficiente às tradicionais ferramentas GNU Autotools, como autoconf, automake e libtool.
Uma das características principais do mk-configure é a sua abordagem declarativa para escrever Makefiles.
Em vez de especificar detalhadamente como construir o software, os desenvolvedores simplesmente listam os arquivos fonte, arquivos a serem construídos e, opcionalmente, opções de compilação. Isso torna o processo de construção mais simples e menos propenso a erros.
VOLTAR AO TOPO VOLTAR AO ÍNDICEÚltima edição por ADRIANNO em Sex 05 Abr 2024, 9:44 pm, editado 29 vez(es)
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:29 pm
por ADRIANNO Ter 07 Nov 2023, 1:29 pm
VOLTAR AO ÍNDICE PRÓXIMA PÁGINAman
- Código:
man comando
- +informações:
- Manual dos comandos, antes de qualquer comando escreva: man
O comando "man" mostra as funções de outros comandos. Ele exibe a documentação oficial. versão online
Suponha que você deseja obter informações sobre o comando "ping",
que é usado para testar a conectividade com outro dispositivo na rede.
Para isso, você pode digitar "man ping" na linha de comando.
O comando "man ping" irá exibir a documentação oficial do comando "ping",
que inclui informações sobre os sintaxes, os parâmetros, os argumentos e exemplos de uso.
Para concluir, "man" ajuda os usuários a entender melhor o Linux.
argumentos usados para personalizar a saída do comando:
man -f ping mostra uma versão curta, fica parecendo uma saída de comando.
man -k disk para realizar uma busca abrangente por documentações relacionadas a "disco" em todo o sistema.
pwd
- Código:
pwd
- +informações:
- Ao executar o comando pwd, o shell exibirá a informação do diretório atual em que o terminal está trabalhando,
Isso é útil para ver a estrutura do diretório atual, mostrado em forma de string de texto.
Esse comando é muito útil quando você precisa sair do diretório atual por um momento, é depois saber para onde voltar,
ou quando precisar compartilhar o caminho do diretório atual com outras pessoas.
cd
- Código:
cd caminho
- +informações:
- O comando cd "change directory" é usado para mudar o diretório atual.
Quando você usa o comando cd, ele mudará o diretório atual para o diretório especificado.
O comando cd possibilita a navegação pela estrutura de diretórios, permitindo o acesso a arquivos e a execução de comandos em locais específicos.
exemplo:
Para navegar para um diretório específico.
Vamos navegar até o diretório /home/usuário/documentos independentemente do diretório atual, basta fazer isso:
cd /home/usuário/documentos
Quando você navega para um diretório específico usando o comando cd, o shell muda seu diretório de trabalho para esse local.
A partir desse momento, o shell considera esse diretório como o diretório de trabalho atual.
Ao executar comandos ou referenciar arquivos e diretórios dentro desse diretório, o shell já sabe que você está trabalhando dentro dele.
Portanto, não é necessário especificar o caminho completo dos arquivos ou diretórios que estão dentro desse diretório,
porque o shell automaticamente busca por eles dentro do diretório atual.
Por exemplo, se você estiver dentro do diretório /home/flyer/Músicas/,
e quiser acessar um arquivo chamado música1.mp3 que está dentro da pasta best2023, você só precisa digitar:
cd best2023
O shell entenderá que você deseja entrar no diretório best2023, que está dentro do diretório atual /home/flyer/Músicas/.
Similarmente, se você quiser excluir o arquivo música2.mp3 que está dentro da pasta best2024, você pode simplesmente digitar:
rm best2024/música2.mp3
O shell já sabe que você está trabalhando dentro do diretório /home/flyer/Músicas/, então não é necessário especificar o caminho completo para o arquivo.
Essa funcionalidade torna a navegação e manipulação de arquivos muito mais conveniente e eficiente,
pois você não precisa repetir o caminho completo várias vezes enquanto trabalha dentro de um determinado diretório.
Existe uma maneira de navegar até um diretório sem precisar digitar todo seu nome, você pode usar a conclusão de tabulação automática do shell.
Comece digitando os primeiros caracteres da pasta e, em seguida, pressione a tecla Tab para que o shell complete automaticamente o nome da pasta para você.
Se houver várias pastas com nomes semelhantes, pressione a tecla Tab duas vezes para exibir todas as opções correspondentes.
Em muitos casos, precisamos navegar para diretórios cujos nomes são muito longos, para evitar digitar o nome completo do diretório, podemos utilizar o caractere asterisco *
que é um curinga que corresponde a qualquer sequência de caracteres. Quando combinado com o comando cd, o shell expande esse asterisco para corresponder a qualquer diretório cujo nome comece com o texto fornecido.
Por exemplo, se quisermos navegar para o diretório /home/flyer/Vídeos/Nova pasta
Podemos estabelecer padrões dessa forma, e o asterisco preenche o restante automaticamente:
cd /home/flyer/Vídeos/Nova\ past*
cd /home/flyer/Vídeos/Nova\ pas*
cd /home/flyer/Vídeos/Nova\ pa*
cd /home/flyer/Vídeos/Nova\ p*
cd /home/flyer/Vídeos/Nova\ *
cd /home/flyer/Vídeos/Nova*
cd /home/flyer/Vídeos/N*
Propositalmente optei por um diretório que usa espaços em seu nome: Nova pasta, nesses casos para poder usar caracteres curinga,
não se deve utilizar o nome do diretório entre aspas"Nova pasta"
Para representar espaços, use a barra invertida, exemplo: Nova\ pasta
Quando existem múltiplos diretórios cujos nomes também começam com o padrão fornecido, o comando cd emitirá um alerta:
bash: cd: número excessivo de argumentos
Por outro lado, se houver apenas um diretório que corresponda ao padrão, o comando cd funcionará bem com o caractere curinga.
Navegar para o diretório pai.
Use o comando cd .. (cd ponto pronto) para mudar um nível de diretório atrás, ou seja, voltar ao diretório anterior.
se você está em "/home/usuário/documentos" e deseja voltar ao diretório pai "/home/usuário",
cd ..
Para retornar para o diretório anteriormente visitado.
Isso é útil para alternar entre dois diretórios rapidamente sem precisar digitar o caminho completo novamente.
o shell muda para o diretório anteriormente acessado, porque o último diretório visitado é registrado na variável de ambiente $OLDPWD
cd -
Se digitar o comando cd sozinho ele voltará para o diretório home.
Outra forma de navegar para o diretório pessoal do usuário:
cd ~
Navegar para o diretório raiz:
cd /
Vou apresentar outra forma de navegar pelos diretórios.
O comando cd ../nome_da_pasta serve para navegar de um subdiretório para outro, onde ambos estão dentro do mesmo diretório pai.
Ele permite que você se mova dentro dessa hierarquia pai sem precisar especificar o caminho completo das pastas.
Por exemplo, imagine que você esteja dentro do diretório /home/flyer/documentos/ e dentro tenha três pastas chamadas: projeto1 projeto2 projeto3
Entrei em /home/flyer/documentos/ assim:
cd /home/flyer/documentos/
Agora quero entrar em projeto1
cd projeto1
Para ir do projeto1 para o projeto2, não posso usarcd projeto2, já que o projeto2 não está localizado dentro do projeto1, mas sim dentro da pasta "documentos".
Nesse caso, você precisaria especificar o caminho completo cd /home/flyer/documentos/projeto2, mas podemos simplificar utilizando:
cd ../projeto2
Já dentro de projeto2 para ir para o projeto3, ambos localizados dentro da pasta "documentos", você executa:
cd ../projeto3
Para voltar ao diretório /home/flyer/documentos/ estando dentro de projeto3. Ou seja, voltar um nível na hierarquia de diretórios.
Observação: Se ficar usando esse comando repetidamente, em algum momento você voltará todos os níveis até chegar no diretório raiz.
cd ../.
Já esse outro comando voltará de dois em dois níveis de hierarquia.
cd ../..
É o mesmo que usar cd .. para voltar um nível:
cd ..
ls
- Código:
ls opções caminho
- +informações:
- o comando ls é usado para listar os arquivos e pastas de um diretório.
Ele exibe informações sobre cada arquivo e pasta, incluindo o nome, tamanho, tipo de arquivo e data de modificação (timestamp).
O ls pode ser usado com várias opções para ajustar a forma como os arquivos são listados:
sintaxe comum:
ls -l Listar arquivos e diretórios no diretório atual com informações detalhadas, incluindo permissões, tamanho, proprietário e grupo.
ls -h H mostra os arquivos em bytes, megabytes ou gigabytes.
ls -a lista todos os arquivos e pastas, incluindo arquivos ocultos.
ls -t Listar arquivos por data de modificação reversa (do mais recente para o mais antigo)
ls -r Listar arquivos e diretórios em ordem alfabética inversa (do Z ao A)
ls -R Lista todos os arquivos e pastas, subpastas dentro de outras subpastas (ou seja, pastas aninhadas)
ls -R | grep ":$" Lista todas as subpastas dentro de outras subpastas, mas apenas as pastas e não mostra nenhum arquivo.
ls -S Listar arquivos por tamanho em ordem crescente (do menor para o maior)
obs:. O shell é sensível a maiúsculas e minúsculas.
Para listar os arquivos e diretórios no diretório atual cujos nomes começam com 2023,
você pode utilizar um asterisco * como caractere curinga, indicando que podem existir outros caracteres após 2023.
ls 2023*
Isso listará todos os arquivos e diretórios no diretório Imagens da sua pasta pessoal, cujos nomes iniciam com 2023.
Especificando o caminho completo, você pode listar qualquer diretório sem a necessidade de se deslocar usando o comando cd.
ls $HOME/Imagens/2023*
Esse comando é utilizado para listar todos os arquivos no diretório atual que possuem a extensão .txt
O shell irá enumerar todos os arquivos no diretório atual cujos nomes se encerram com .txt
ls *.txt
Listar todos os arquivos com extensão .png de um diretório que não é o diretório atual:
ls $HOME/Imagens/*.png
ls /etc/*.conf
ls /bin/*.sh
Para exportar todo o conteúdo de um diretório em formato de arquivo de texto, criando uma lista dos nomes de pastas e arquivos, e assim, poder compartilhá-la com alguém ou para fins de armazenamento.
obs:. empregamos a variável de ambiente $HOME, que se refere ao caminho do diretório pessoal do usuário.
ls "$HOME/Nova pasta/4/" > arquivotexto.txt
Para listar o conteúdo do diretório mais as subpastas e todos os arquivos, usaremos o comando ls com a opção -R para listar recursivamente.
Optaremos por salvar a saída em um arquivo de texto, em vez de exibi-la no terminal.
ls -R "$HOME/Nova pasta/4/" > arquivotexto2.txt
Este comando é utilizado para gerar uma lista do espaço ocupado pelos arquivos, em um diretório e suas subpastas de maneira recursiva.
Calculando o tamanho de cada arquivo. Os resultados serão organizados em ordem decrescente.
Optaremos por salvar a saída em um arquivo de texto para futuras referências ou análises, em vez de exibi-la no terminal.
ls -RlhS "$HOME/Nova pasta/4/" > arquivotexto3.txt
Lista os arquivos de um diretório por data de modificação, do mais recente para o mais antigo:
ls -ltr /var/cache/pacman/pkg/
Esse comando exibirá o nome completo do último arquivo modificado:
ls -ltr /var/cache/pacman/pkg/ | tail -n 1
df
- Código:
df opções caminho
- +informações:
O comando "df" (disk free) é usado para mostra o espaço em disco disponível,
como o espaço total, espaço usado e espaço livre em disco.
Quando executado sem nenhum argumento, o comando "df" exibe informações sobre todos os sistemas de arquivos montados.
argumentos usados para personalizar a saída do comando:
df -h --human exibe os valores de forma legíveis pelo ser humano, como GB, MB ou KB.
df -ht --type A listagem deve mostrar só esse tipo de sistemas de arquivos df -ht ext4
df -hT --print-type Exibe o tipo de sistema de arquivos de todas as partições.
df -hx --exclude Remove da listagem esse tipo de sistemas de arquivos df -hx ext4
du sort head
- Código:
du opções caminho
- +informações:
- O comando du (disk usage) mostra o tamanho total ocupado por um determinado arquivo ou diretório, incluindo o tamanho de todos os seus subdiretórios e arquivos.
Isso exibirá o tamanho de cada diretório dentro do diretório especificado, usando o caractere curinga * para listar todos os diretórios dentro dele.
du -sh /usr/bin/*
Exibir o tamanho de um diretório e seus subdiretórios em ordem decrescente:
du -sh /usr/bin/* | sort -rh
Calcula o uso de disco no diretório /home, esse comando só tem sentido se houver mais de um usuário no home.
du -h -d 1 /home
Localize os 10 maiores arquivos em todos os diretórios pessoais (home) de todos os usuários, incluindo seus subdiretórios dentro de subdiretórios.
du -ahm /home | sort -n -r | head -n 10
Identifique os 10 maiores arquivos no diretório pessoal (home) do usuário atual, incluindo seus subdiretórios dentro de subdiretórios.
du -ahm $HOME/ | sort -n -r | head -n 10
Identifique os 15 maiores arquivos no diretório pessoal (home) do usuário atual, para todos os subdiretórios, mas não para subdiretórios aninhados.
du -Sh | sort -rh | head -15
Realiza uma análise superficial do uso de disco em todos os arquivos do diretório atual, superficial porque exclui subdiretórios.
du -hs * | sort -rh | head -15
cp
- Código:
cp opções origem1 origem2 destino
- +informações:
- cp (abreviação de copy) = Cópia arquivos. Copiar estruturas de diretórios inteiras, preservando as permissões, propriedades e timestamps dos arquivos.
Aqui estão algumas opções comuns do comando cp:
-r ou --recursive: realiza uma cópia recursiva de diretórios, ou seja, copia todos os arquivos e subdiretórios dentro do diretório de origem para o diretório de destino.
-i ou --interactive: pede uma confirmação antes de sobrescrever um arquivo existente.
-u ou --update: copia apenas arquivos de origem que são mais recentes do que os arquivos de destino correspondentes ou quando não existe um arquivo de destino.
-v ou --verbose: exibe informações detalhadas sobre o processo de cópia.
-p ou --preserve: preserva as permissões de arquivo, timestamps e outras propriedades dos arquivos copiados.
cópia o arquivo para outrapasta
cp -i arquivo.txt /outrapasta
cópia a pasta para dentro dessa outrapasta
cp -i $HOME/pasta /outrapasta
Nesse exemplo, o asterisco (*) é usado para indicar que queremos copiar todos os arquivos e subpastas dentro das pasta1 e pasta2, sem copiar a pasta pai.
cp -r pasta1/* pasta2/* novapasta/
Vamos copiar o arquivo hostname para o diretório atual. O ponto . representa o diretório atual.
cp /etc/hostname .
mv
- Código:
mv OPÇÕES ORIGEM DESTINO
- +informações:
- mv = Recorta arquivos
Ele move os arquivos de um local para outro ou renomeia esses arquivos.
Aqui estão algumas opções comuns usadas com o comando mv:
-i: Solicita confirmação antes de substituir um arquivo de destino existente.
-v: Modo verboso, exibe informações detalhadas sobre as operações realizadas pelo comando mv.
-u: Move apenas arquivos de origem que são mais recentes do que os arquivos de destino correspondentes ou que não existem nos destinos.
-n: Não substitui um arquivo de destino existente. Se um arquivo de destino com o mesmo nome já existir, o comando mv não fará nada.
Mover um arquivo para outro diretório:
mv arquivo.txt pasta_destino/
Renomear um arquivo:
mv arquivo_antigo.txt arquivo_novo.txt
Mover vários arquivos para um diretório:
mv arquivo1.txt arquivo2.txt pasta_destino/
Renomear um diretório:
mv diretório_antigo/ diretório_novo/
A opção -b garantirá que, se houver conflitos de nomes entre os arquivos de ambas as pastas, eles serão renomeados automaticamente para evitar sobreposições.
movendo arquivos .txt para 'outra pasta'
mv -b "$HOME/nova pasta"/*.txt "$HOME/outra pasta/"
VOLTAR AO TOPO VOLTAR AO ÍNDICEÚltima edição por ADRIANNO em Dom 31 Mar 2024, 9:47 am, editado 16 vez(es)
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:30 pm
por ADRIANNO Ter 07 Nov 2023, 1:30 pm
Última edição por ADRIANNO em Qua 15 Nov 2023, 4:48 pm, editado 3 vez(es)
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:30 pm
por ADRIANNO Ter 07 Nov 2023, 1:30 pm
VOLTAR AO ÍNDICE PRÓXIMA PÁGINArm
- Código:
rm opções arquivos ou diretórios
- +informações:
O comando rm é uma abreviação de remove.
Ele é usado para excluir arquivos e diretórios do sistema de arquivos.
É um comando para ser usado com cautela, pois os arquivos e diretórios excluídos não são movidos para a lixeira, eles são removidos permanentemente sem pedir confirmação.
Para excluir um diretório especifique corretamente o caminho. Para excluir arquivos para os quais seu usuário possui permissão, como arquivos do sistema ou diretórios protegidos, é necessário usar o comando com sudo para executá-lo como superusuário.
Existem algumas diferenças no modo como você deve usá-lo para cada tipo de arquivo.
Para remover arquivos, o comando rm vem seguido do nome do arquivo que deseja excluir.
rm arquivo.txt
para remover diretórios, você precisa adicionar a opção -r recursivo.
Isso ocorre porque os diretórios podem conter vários arquivos e outros subdiretórios, e você precisa remover pastas recursivamente.
rm -r diretorio
Aqui estão alguns dos parâmetros mais comuns do comando rm
-f Força a exclusão dos arquivos/diretórios sem solicitar confirmação. Ignora mensagens de erro e não emite avisos.
-i Interativo. Solicita confirmação antes de excluir cada arquivo. Isso permite que o usuário confirme ou cancele a exclusão de cada arquivo individualmente.
-r ou -R Remove recursivamente diretórios e seus conteúdos. Normalmente usado quando você deseja excluir um diretório e todos os arquivos e subdiretórios.
-v ou --verbose Exibe mensagens detalhadas sobre as ações realizadas pelo comando, como os arquivos que estão sendo excluídos.
--preserve-root Isso é uma medida de segurança para evitar a exclusão acidental de todos os arquivos do sistema operacional, não usar com o sudo.
Se você procura uma maneira de apagar arquivos de forma definitiva, tornando a recuperação de dados impossível, o comando shred é a solução.
Ele é utilizado para eliminar permanentemente arquivos ou dispositivos de armazenamento, como discos rígidos ou partições, tornando os dados irreconhecíveis e inacessíveis.
Se deseja automatizar a exclusão de arquivos sem a necessidade de digitar manualmente a sintaxe do comando, basta fornecer o caminho do arquivo nesse script.
shred [OPÇÕES] NOME_DO_ARQUIVO
Sobrescrever um arquivo uma vez com zeros e removê-lo:
shred -z -u arquivo.txt
Sobrescrever um arquivo cinco vezes com padrões aleatórios e remover:
shred -n 5 -u arquivo.txt
Esse comando irá sobrescrever todo o conteúdo do disco sda, incluindo a tabela de partições.
Sobrescrever um dispositivo de armazenamento inteiro três vezes com padrões aleatórios:
shred -n 3 /dev/sda
sobrescreve cinco vezes todos os dados no primeiro disco rígido do sistema /dev/sda
shred -v -n 5 -z -u /dev/sda
Este comando usa find para localizar arquivos no diretório descrito.
Em seguida, ele executa shred em cada arquivo encontrado, sobrescrevendo-o cinco vezes com dados aleatórios
find /home/usuário/diretório -depth -type f -exec shred -v -n 5 -z -u {} \;
Limpar lixeira definitivamente.
find /home/flyer/.local/share/Trash/files -depth -type f -exec shred -v -n 5 -z -u {} \;
Opções comuns do shred:
-n Especifica o número de vezes que o arquivo deve ser sobrescrito.
-z Sobrescreve o arquivo com zeros após a última iteração.
-u Remove o arquivo após a sobrescrita.
-v Exibe informações detalhadas sobre o progresso do comando.
-f Força a operação, ignorando avisos de permissão ou arquivos de dispositivo.
file
- Código:
file ARQUIVO
- +informações:
- uma ferramenta para identificar arquivos, especialmente quando a extensão do arquivo é ambígua ou inexistente.
Determina o tipo de arquivo com base em seu conteúdo, em vez de depender apenas da extensão do nome do arquivo.
Ele funciona analisando os primeiros bytes do arquivo e comparando-os com um banco de dados de assinaturas de tipos.
Foi identificado como sendo um arquivo de texto ASCII
Pois contém configurações de localização (locales) informações relacionadas à localização no sistema.
file /etc/locale.gen
-i descreve o formato e a natureza dos arquivos, ele especifica que o tipo de conteúdo é "text/plain" (texto simples) e a codificação de caracteres é "us-ascii".
file -i /etc/locale.gen
Foi identificado como um executável no formato ELF (Executable and Linkable Format) de 64 bits, é dinamicamente vinculado a bibliotecas /usr/lib/ld-linux-x86-64.so.2
Ele é um executável PIE, o que significa que foi compilado como um executável de posição independente, o que geralmente é usado para melhorar a segurança do programa.
file /bin/locale
Segue links simbólicos e fornece informações sobre o arquivo para o qual o link aponta.
file -L link_simbolico
file -L /etc/localtime
file -L /etc/os-release
Foi identificado como um arquivo de imagem no formato JPEG (Joint Photographic Experts Group) Padrão JFIF standard 1.01, uma resolução de 2880x1800 pixels.
O arquivo possui informações sobre a resolução em DPI (dots per inch), com uma densidade de 150x150 DPI.
Possui precisão de 8 bits por componente, aqui são 3 componentes de cor, indicando que é uma imagem colorida com canais de vermelho, verde e azul (RGB).
O arquivo é do tipo progressivo, o que significa que pode ser carregado gradualmente em conexões de internet lentas.
file /usr/share/backgrounds/xfce/xfce-blue.jpg
foi identificado como um arquivo de dados comprimido no formato Zstandard (Zstd). O "Dictionary ID: None" indica que o arquivo não está usando um dicionário para a compressão. A compressão com Zstandard é uma técnica comum para compactar arquivos de inicialização, pois pode ajudar a economizar espaço em disco e acelerar o processo de inicialização.
sudo file /boot/initramfs-linux.img
foi identificado como um script shell POSIX no formato ASCII. (com um total de 1352 caracteres).
file /boot/grub/i386-pc/modinfo.sh
Foi identificado como um arquivo de áudio (Ogg data). Canal de áudio em estéreo, com uma taxa de amostragem de 22050 Hz, Taxa de bits: 88000 bps por segundo.
No formato Vorbis, que é um formato de compressão de áudio sem perdas, o som específico, service-login.oga, é um som de notificação associado ao processo de login encontrado no pacote sudo pacman -S sound-theme-freedesktop
file /usr/share/sounds/freedesktop/stereo/service-login.oga
iconv
- Código:
iconv -f ENCODING_ORIGEM -t ENCODING_DESTINO [OPÇÕES] ARQUIVO_ORIGEM > ARQUIVO_DESTINO
- +informações:
- Codificações de Caracteres:
O comando iconv é empregado para realizar a conversão da codificação de caracteres de um arquivo de texto, possibilitando a transição de uma codificação para outra.
A codificação de caracteres refere-se à maneira pela qual os caracteres são representados em formato binário, permitindo que os computadores processem e exibam o texto de forma compreensível aos humanos.
Diversas codificações de caracteres estão disponíveis, cada uma delas possuindo regras específicas para a atribuição de valores binários a caracteres individuais.
Existe uma tabela que mapeia e associa cada caractere a um valor binário, enquanto as fontes de letras (ou fontes tipográficas) são responsáveis pela exibição visual,
incluindo atributos como itálico, negrito, etc, como Arial, Times New Roman, Helvetica, etc.
As codificações estabelecem padrões de máquina, detalhes como o design, tamanho e estilo da letra não trazem problemas de exibição pois são um Font-End das codificações. Mas, a incompatibilidade na codificação vai gerar problemas em seu arquivo de texto.
Se um texto estiver codificado de uma maneira e for exibido usando uma codificação diferente, vai ocorrer problemas de exibição, tais como caracteres incorretos, espaços em branco ou até mesmo a falta de alguns caracteres.
Os diferentes aplicativos que abrem arquivos de texto utilizam uma codificação específica, e, para se ajustar a esse contexto, a conversão dessa codificação é necessária.
Sintaxe:
iconv -f ENCODING_ORIGEM -t ENCODING_DESTINO [OPÇÕES] ARQUIVO_ORIGEM > ARQUIVO_DESTINO
-f ENCODING_ORIGEM: Especifica a codificação de caracteres original do arquivo. Sim, você precisa saber a codificação do arquivo original.
-t ENCODING_DESTINO: Especifica a codificação de caracteres para a qual o arquivo deve ser convertido. Escolha a codificação final desse arquivo.
ARQUIVO_ORIGEM: O nome do arquivo de entrada que você deseja converter.
ARQUIVO_DESTINO: O nome do arquivo de saída, que conterá o texto convertido.
Por exemplo, se você tem um arquivo chamado arquivo_utf8.txt codificado em UTF-8 e deseja convertê-lo para ISO-8859-1, você usaria o comando:
iconv -f utf-8 -t iso-8859-1 arquivo_utf8.txt > arquivo_iso8859.txt
invertendo:
iconv -f iso-8859-1 -t utf-8 arquivo_iso8859.txt > arquivo_utf8.txt
Para identificar a codificação de um arquivo use os comandos: file ou chardet.
Aqui estão algumas das codificações de caracteres mais comuns:
UTF-8: Universal Character Set Transformation Format 8-bits. Uma codificação de caracteres Unicode muito flexível e amplamente utilizada. Suporta todos os caracteres Unicode e é compatível com ASCII.
UTF-16: Similar ao UTF-8, mas utiliza 16 bits para representar caracteres. É comumente usado em sistemas Windows e para processar caracteres que exigem mais de 16 bits.
UTF-32: Usa 32 bits para representar cada caractere, tornando-o mais eficiente para caracteres fora do BMP (Basic Multilingual Plane). Menos comum em comparação com UTF-8 e UTF-16.
ISO-8859-1 (Latin-1): Amplamente utilizado para idiomas europeus. Mapeia os primeiros 256 caracteres Unicode para os primeiros 256 códigos de caracteres ASCII.
ISO-8859-15: Uma extensão do ISO-8859-1 que inclui caracteres adicionais, como o euro (€).
Windows-1252: Uma extensão do ISO-8859-1 com suporte a caracteres adicionais, utilizado principalmente em sistemas Windows.
ASCII: American Standard Code for Information Interchange. A codificação de caracteres originalmente desenvolvida para representar texto em inglês. Usa 7 bits para representar caracteres.
Shift JIS: Uma codificação de caracteres amplamente utilizada no Japão.
EUC-JP: Extended UNIX Code-JP, outra codificação de caracteres japonesa usada em sistemas UNIX.
GBK (GB 18030): Conjunto de caracteres simplificado usado principalmente na China.
KOI8-R: Uma codificação de caracteres usada para idiomas eslavos.
Lembre-se de que a escolha da codificação depende do contexto e dos requisitos específicos do aplicativo que vai abrir esse arquivo.
Instale fontes extras para usar idiomas não latinos.
Incluir todos os glifos necessários para cada idioma em uma única fonte seria impraticável devido ao tamanho do arquivo e à complexidade associada.
Quando você tenta exibir caracteres coreanos em um sistema operacional configurado para um idioma latino e vê quadrados em vez dos caracteres,
o problema geralmente está relacionado à falta de suporte à fonte necessária para os caracteres coreanos.
UTF-8 é uma codificação amplamente utilizada que suporta caracteres de vários idiomas, incluindo coreano.
Fontes como Arial, Times New Roman e Helvetica são fontes ocidentais e não contêm os caracteres Hangul necessários para escrever em coreano.
Portanto, ao escrever em coreano, você deve selecionar fontes que tenham suporte adequado para o Hangul.
Existem fontes específicas projetadas para lidar com conjuntos de caracteres asiáticos, incluindo o coreano.
Exemplos de fontes que oferecem suporte ao Hangul incluem "Noto Sans CJK", "Malgun Gothic" e "Gulim"
A necessidade de instalar fontes específicas para idiomas como chinês, coreano, árabe e russo está relacionada à diversidade de caracteres e glifos utilizados nesses idiomas, que muitas vezes não estão presentes nas fontes padrão projetadas para idiomas latinos.
mkdir
- Código:
mkdir caminho
- +informações:
- mkdir = Cria uma pasta
Criar um diretório simples
mkdir ~/nome_da_pasta
Para criar um diretório oculto no Linux, use um ponto . no início do nome dessa pasta:
mkdir ~/.pasta_oculta
Criar um diretório dentro de outro diretório existente "nome_da_pasta"
mkdir ~/nome_da_pasta/pasta_interna
Criar vários diretórios de uma vez:
mkdir pasta1 pasta2 pasta3
Use o argumentos -m para especificar as permissões da pasta a ser criada:
mkdir -m755 ~/novapasta
Use o argumentos -p para conseguir criar diretórios pai, ou seja, você cria pastas dentro dessa pasta pai "subdiretórios" ou "diretórios aninhados"
mkdir -p ~/pastapai/outrapasta/últimapasta
Criando nomes aleatórios para suas pastas.
1) Com o comando mktemp, é possível criar uma pasta no diretório HOME com um nome aleatório de três dígitos ou mais.
tempdir=$(mktemp -d "$HOME/XXX")
2) Neste exemplo, serão criadas 15 pastas com nomes aleatórios em minha HOME.
for i in {1..15}; do mkdir -p "$(mktemp -d $HOME/XXX)"; done
3) Neste outro exemplo, criaremos uma pasta principal e dentro dela criaremos 10 subpastas numeradas.
flyerdir=$(mktemp -d $HOME/XXX) && for i in {1..10}; do mkdir -vp "$flyerdir/$i"; done
obs: uma forma conveniente de referenciar o diretório home sem precisar especificar o caminho completo e usar "~/" ou "$HOME"
o shell substitui ~/ pelo caminho do diretório home antes de executar o comando.
Esses recursos são suportados em shells Unix-like, como o Bash, o Zsh e o Csh.
find
- Código:
find caminho opções ações
- +informações:
- O comando find é especialmente útil quando você precisa localizar arquivos com base em critérios específicos e executar ações nesses arquivos encontrados.
- Exercícios para praticar com o comando:
- Para treinarmos a pesquisa de arquivos em diretórios, crie alguns arquivos de texto e pastas para fins de teste. Se desejar, você pode utilizar o meu exemplo como referência:
- Código:
mkdir -vp pasta_família pasta_família/pasta_avó/{pasta_tio,pasta_tia}/{pasta_primo,pasta_prima} pasta_família/pasta_avô/{pasta_pai,pasta_mãe}/{pasta_filho,pasta_filha} && touch pasta_família/pasta_avó/pasta_tio/tio.txt && touch pasta_família/pasta_avó/pasta_tia/tia.txt && touch pasta_família/pasta_avó/pasta_tio/pasta_primo/primo.txt && touch pasta_família/pasta_avó/pasta_tio/pasta_prima/prima.txt && touch pasta_família/pasta_avó/pasta_tia/pasta_prima/prima.txt && touch pasta_família/pasta_avó/pasta_tia/pasta_primo/primo.txt && touch pasta_família/pasta_avô/pasta_pai/pai.txt && touch pasta_família/pasta_avô/pasta_mãe/mãe.txt && touch pasta_família/pasta_avô/pasta_pai/pasta_filho/filho.txt && touch pasta_família/pasta_avô/pasta_pai/pasta_filha/filha.txt && touch pasta_família/pasta_avô/pasta_mãe/pasta_filha/filha.txt && touch pasta_família/pasta_avô/pasta_mãe/pasta_filho/filho.txt
Após a criação de todos esses diretórios, prosseguiremos com algumas atividades envolvendo essas pastas.
veja como ficou essa criação: ls -RlhS "$HOME/pasta_família"- output:
- "$HOME/pasta_família"
"$HOME/pasta_família/pasta_avó"
"$HOME/pasta_família/pasta_avó/pasta_tio"
"$HOME/pasta_família/pasta_avó/pasta_tio/pasta_primo"
"$HOME/pasta_família/pasta_avó/pasta_tio/pasta_prima"
"$HOME/pasta_família/pasta_avó/pasta_tia"
"$HOME/pasta_família/pasta_avó/pasta_tia/pasta_primo"
"$HOME/pasta_família/pasta_avó/pasta_tia/pasta_prima"
"$HOME/pasta_família/pasta_avô"
"$HOME/pasta_família/pasta_avô/pasta_pai"
"$HOME/pasta_família/pasta_avô/pasta_pai/pasta_filho"
"$HOME/pasta_família/pasta_avô/pasta_pai/pasta_filha"
"$HOME/pasta_família/pasta_avô/pasta_mãe"
"$HOME/pasta_família/pasta_avô/pasta_mãe/pasta_filho"
"$HOME/pasta_família/pasta_avô/pasta_mãe/pasta_filha"
Com este comando, procuraremos arquivos dentro da pasta_avô e, se encontrarmos algum, faremos uma cópia deles para a pasta_família.
find "$HOME/pasta_família/pasta_avô" -type f -exec cp -i {} "$HOME/pasta_família/" \;
para buscar arquivos em duas pastas distintas, onde ambas possuem subpastas, com o desafio de lidar com arquivos repetidos para evitar conflitos, usaremos cp -i
find "$HOME/pasta_família/pasta_avô" "$HOME/pasta_família/pasta_avó" -type f -name "*.txt" -exec sh -c 'cp -i "$1" "$HOME/pasta_família/$(basename "$1")"' _ {} \;
Esta nova modificação no código utiliza o comando mv com a opção -b (backup) para procurar em duas pastas e suas subpastas em busca de arquivos .txt.
Quando encontra esses arquivos, cria um backup deles na pasta 'pasta_família'. Se existirem arquivos com o mesmo nome, o arquivo é automaticamente renomeado.
find "$HOME/pasta_família/pasta_avô" "$HOME/pasta_família/pasta_avó" -type f -name "*.txt" -exec mv -b {} "$HOME/pasta_família/" \;
O comando find fará uma busca em todos os diretórios e subdiretórios da Home do usuário, uma busca por imagens com extensão: jpg, png e gif.
find "$HOME/" -type f \( -name "*.jpg" -o -name "*.png" -o -name "*.gif" \)
para copiar todas as imagens encontradas na Home para a pasta pasta_família
find "$HOME/" -type f \( -name "*.jpg" -o -name "*.png" -o -name "*.gif" \) -exec cp -t "$HOME/pasta_família" {} +
FIM
########################################################################
Este comando busca recursivamente todos os arquivos e diretórios e seus subdiretórios.
find "diretório_aqui"
Essas opções de mindepth e maxdepth permitem controlar a profundidade da busca do find.
O find não incluirá o diretório base em sua busca, mas continua a procurar em subdiretórios desse diretório base.
find "diretório_aqui" -mindepth 1
o find está limitado a procurar apenas dentro do diretório citado sem verificar os subdiretórios.
find "diretório_aqui" -maxdepth 1
Para uma procura básica por um nome "Linux", independentemente de estar em maiúsculas ou minúsculas.
Redirecionamos as mensagens de erro para /dev/null, suprimindo possíveis mensagens de permissão negada ou diretórios inacessíveis.
find / -iname "Linux" 2>/dev/null
Usa os caracteres curingas ? * para buscar nomes de arquivo que começam com duas letras quaisquer, seguidas pelas letras of na terceira e quarta posição.
A partir da quinta posição e além, o padrão aceita qualquer combinação de caracteres adicionais.
Isso significa que o comando encontrará todos os arquivos e diretórios cujos nomes se encaixem nesse critério.
find $HOME/ -name '??of*'
Busca todos os arquivos no diretório atual e seus subdiretórios, calcula o uso de disco para esses arquivos, e exibe os 15 maiores arquivos encontrados.
find -type f -exec du -Sh {} + | sort -rh | head -n 15
Lista todos os arquivos e pastas, subpastas dentro de outras subpastas (pastas aninhadas) com o caminho completo para cada item.
find /home/flyer/.steam/steam/ -type d
Busca única: Esse comando procura apenas por arquivos, não diretórios, dentro do diretório /var/cache/pacman/pkg/ cujo nome contenha opencl.
find /var/cache/pacman/pkg/ -type f -name "*opencl*"
Busca dupla: Esse comando procura apenas por arquivos, não diretórios, dentro do diretório /var/cache/pacman/pkg/ cujos nomes contenham linux e opencl.
find /var/cache/pacman/pkg/ -type f \( -name "*linux*" -o -name "*opencl*" \)
Buscar e copiar: Esse comando procura apenas por arquivos dentro do diretório /var/cache/pacman/pkg/ cujos nomes contenham linux e opencl,
e, em seguida, copia esses arquivos para o diretório /home/flyer/backupPKG/.
find /var/cache/pacman/pkg/ -type f \( -name "*linux*" -o -name "*opencl*" \) -exec cp {} /home/flyer/backupPKG/ \;
O comando find inicia a busca no diretório Home por qualquer arquivo baseado no seu tempo de modificação, vamos exportar o resultado para um arquivo de texto.
valor -ctime -1 significa "menos de 1 dia" portanto nas últimas 24 horas.
valor -cmin -1 significa "menos de 1 minuto"
Isso inclui arquivos cujo conteúdo foi alterado, bem como aqueles cujos atributos (como permissões) foram modificados, pois lista todos os arquivos que tiveram sua metainformação alterada.
find "$HOME/" -type f -ctime -1 > lista.txt
Use o comando find em combinação com mtime (tempo de modificação) para localizar todos os arquivos criados na última hora.
find $HOME -type f -mmin -60
Para encontrar os arquivos recém-adicionados em um diretório, você pode usar o comando find junto com o argumento -newer onde você pode ajustar a data conforme necessário.
find /home/flyer/.steam/steam/steamapps/common/Grim\ Dawn/ -type f -newermt 2023-11-17
Se preferir ver informações extras como: Permissões, usuário, tamanho, data, use o comando ls -l no final:
find /home/flyer/.steam/steam/steamapps/common/Grim\ Dawn/ -type f -newermt 2023-11-17 -exec ls -l {} \;
Vamos usar o find para localizar todos os arquivos que foram modificados após a data especificada (-newermt). Em seguida, utiliza -exec rm {} \; para deletar esses arquivos.
find /home/flyer/.steam/steam/steamapps/common/Grim\ Dawn/ -type f -newermt 2023-11-17 -exec rm {} \;
Para listar apenas os arquivos de vídeo recém-adicionados (últimas 24 horas) em seu diretório barra.
find / -type f -ctime -1 \( -iname "*.mp4" -o -iname "*.mkv" -o -iname "*.avi" -o -iname "*.webm" \)
Outra maneira de buscar arquivos de vídeo no seu diretório $HOME e subdiretórios, ordená-los pelo tempo de modificação e pegar o mais recente:
find $HOME -type f \( -iname \*.webm -o -iname \*.mp4 -o -iname \*.wmv -o -iname \*.avi -o -iname \*.mkv -o -iname \*.flv \) -exec stat --format="%Y %n" {} + | sort -n | tail -n1 | cut -d ' ' -f2-
O comando find irá pesquisa o nome de um executável "xfce4-terminal" dentro da pasta /sbin/
se encontrar um arquivo com esse nome deve executar o comando stat para exibir informações sobre esse arquivo.
find /sbin/ -type f -name "xfce4-terminal" -exec stat {} \;
grep
- Código:
grep opções padrão arquivo
- +informações:
- Para pesquisar texto em arquivos ou fluxos de texto.
Procura por uma palavra em um arquivo de texto(adicione mais de um arquivo se precisar), e imprimir todas as linhas que a contêm.
grep "seu texto aqui" arquivo.txt
Ignorar diferença entre maiúsculas e minúsculas.
grep -i "seu texto aqui" arquivo.txt
Se você deseja identificar um texto específico em meio a vários outros arquivos, o comando a seguir listará apenas os arquivos que contêm o conteúdo desejado.
grep -l "seu texto aqui" arquivo1.txt arquivo2.txt arquivo3.txt arquivo4.txt
Isso procurará recursivamente pelo texto em todos os arquivos dentro do diretório especificado.
grep -r "seu texto aqui" $HOME/
Para procurar a palavra "Linux" em um arquivo de texto, imprimir a linha contendo a palavra e as duas linhas seguintes:
grep -A 2 "Linux" arquivo.txt
Para filtrar as linhas de um arquivo de texto, que contêm a palavra "Permissão negada" e, em seguida excluir essas linhas, deixando as outras linhas.
grep -v 'Permissão negada' arquivo_de_log_completo.txt > novo_arquivo_de_log.txt
Irá imprimir todas as linhas que iniciarem com números.
grep "^[0-9]" arquivo.txt
Busca pela string "LINUX" e, quando encontrada, imprime a localização numérica dessa linha, juntamente com a exibição do conteúdo desta linha.
grep -n "LINUX" arquivo.txt
Nesse outro comando vamos combinar duas ferramentas de linha de comando grep e cut, para imprimir somente o número da linha.
A função do cut é cortar a saída enviada pelo grep, esse corte vai descartar tudo após o caractere de dois pontos :
grep -n "LINUX" arquivo.txt | cut -d ":" -f 1
Vamos interagir ainda mais: Se o comando anterior for bem-sucedido, vamos abrir o arquivo.txt no editor de texto mousepad e posiciona o cursor na linha específica indicada pelo número armazenado na variável linha. O sinal de + é uma convenção em muitos editores de texto para especificar a posição inicial de exibição.
(Pode acontecer de conflitar com as funcionalidades do editor de texto, de lembrar a posição do cursor quando o arquivo é fechado)
linha=$(grep -n "LINUX" arquivo.txt | cut -d ":" -f 1) && mousepad +$linha arquivo.txt
linha=$(grep -n "LINUX" arquivo.txt | cut -d ":" -f 1) && nano +$linha arquivo.txt
linha=$(grep -n "LINUX" arquivo.txt | cut -d ":" -f 1) && vim +$linha arquivo.txt
A opção -o permite que exibamos apenas as partes relevantes do texto. Usando a opção -w, garantimos que estamos procurando a palavra completa +Fogo.
O comando grep realiza a busca no arquivo de texto e, em seguida, a saída é encadeada no próximo comando, o wc, que conta o número de linhas na saída.
grep -o -w '+Fogo' arquivo.txt | wc -l
Comando duplo, Primeiramente, ele conta o número de vezes que uma palavra específica ocorre dentro de um texto, usando (grep -c).
Em seguida, busca e exibe todas as linhas que contêm o texto escolhido (grep -n).
Comecei definindo uma variável com o caminho do arquivo de texto. Em seguida, usei essa variável em ambos os comando (grep -c) e (grep -n).
arquivo="$HOME/entrada.txt" && grep -c "meu texto 1" "$arquivo" && grep -n "meu texto 2" "$arquivo"
cat
- Código:
cat opções arquivo.txt
- +informações:
- O comando "cat" é uma abreviação de "concatenate" (concatenar) e é usado principalmente para exibir o conteúdo de um ou mais arquivos de texto.
cat não é tão usado em scripts como o comando echo. Mas o cat pode combinar vários arquivos em um único fluxo contínuo de saída.
Abre um arquivo:
cat arquivo.txt
Cria um arquivo de texto, e o edita pelo terminal. Após pressionar Enter, insira o texto e, em seguida, pressione Ctrl + D para salvar o arquivo.
cat > arquivo1.txt
Exibir o conteúdo de vários arquivos consecutivos:
cat arquivo1.txt arquivo2.txt arquivo3.txt
Use o comando cat para exibir o conteúdo do arquivo linha por linha e redirecionar a saída para o novo arquivo.
Este comando irá ler o conteúdo de um arquivo do sistema grub.cfg linha por linha e salvar em um novo arquivo chamado grub.txt
sudo cat /boot/grub/grub.cfg > /home/flyer/grub.txt- +informações:
- Quando você precisa copiar o conteúdo de um arquivo sem manter as permissões do arquivo original, use o comando cat.
Ao contrário do comando cp, que preserva todas as propriedades do arquivo original, incluindo permissões de acesso,
o cat simplesmente extrai o conteúdo do arquivo e o redireciona para um novo arquivo.
sudo cat /boot/grub/grub.cfg > /home/flyer/grub.txtsudo cp /boot/grub/grub.cfg /home/flyer/grub.txt
Concatenar(junta) dois arquivos em um único arquivo:
cat arquivo1.txt arquivo2.txt > arquivo_final.txt
Exibir números de linha junto ao conteúdo:
cat -n arquivo.txt
mostra as características e detalhes da CPU, como arquitetura, a frequência de clock, a quantidade de núcleos e threads, a quantidade de cache.
cat /proc/cpuinfo
O comando zcat funciona de maneira semelhante ao comando cat, mas é projetado especificamente para arquivos compactados com o gzip.
zcat /usr/share/man/man1/tty.1.gz
Se você estiver lidando com arquivos compactados em outros formatos, como bzip2 (.bz2) ou compress (.Z), você precisará usar as ferramentas correspondentes, como bzcat
O comando tac é uma abreviação de cat ao contrário. Ele é utilizado para visualizar um arquivo de texto de forma reversa, começando pelo final e indo em direção ao início.
Essa funcionalidade é especialmente útil para uma leitura de logs.
tac arquivo.txt
less
- Código:
less arquivo.txt
- +informações:
- O comando less é usado para exibir o conteúdo de um arquivo de forma paginada, permitindo que você role para cima e para baixo, procure por palavras-chave e navegue pelo arquivo de maneira mais flexível.
Exibir o conteúdo de um arquivo:
less arquivo.txt
Paginador para ler longas saídas de texto: (teclas de atalho: PageUP/PageDown/Home/End/space/1/q para sair)
less /var/log/pacman.log
Utilize o comando less para paginar a saída de programas extensos quando seu terminal TTY não suportar rolagem pela janela.
Para paginar a saída do comando ping para o endereço IP 8.8.8.8
ping 8.8.8.8 | less
Dentro do utilitário less, você não pode interagir diretamente com comandos interativos, em que é necessário responder a uma pergunta com S ou n, para esses casos use --noconfirm.
sudo pacman -Syu --noconfirm | less
Espaço: Avança uma página inteira.
B: Retrocede uma página inteira.
G: Vai para o final do arquivo.
/palavra: Inicia uma pesquisa para a palavra-chave especificada. Pressione "n" para encontrar a próxima ocorrência e "N" para encontrar a ocorrência anterior.
h: Exibe a tela de ajuda com uma lista das principais teclas de atalho.
q: Sai do visualizador "less" e retorna ao prompt de comando.
zless funciona de maneira semelhante ao comando less, mas é projetado especificamente para arquivos compactados com o gzip.
zless /usr/share/man/man1/tty.1.gz
echo
- Código:
echo opções texto
- +informações:
- É usado para exibir uma linha de texto ou o valor de uma variável na saída do terminal no Linux. Ele é frequentemente utilizado em scripts de shell para exibir mensagens ou para manipular e mostrar informações aos usuários.
A sintaxe básica:
echo opções texto
Exibir uma mensagem simples:
echo "Olá, mundo!"
Exibir uma variável de ambiente:
echo $HOME
Apaga o conteúdo do arquivo.txt, e escreve "Pudim de Morango"
echo "Pudim de Morango" > arquivo.txt
Mantém o conteúdo do arquivo.txt, e escreve "gelado" no final do arquivo.txt
echo "gelado" >> arquivo.txt
nano
- Código:
nano ~/Documentos
- +informações:
- O Nano é um editor de texto de linha de comando para Linux que oferece uma interface simples e intuitiva para edição de arquivos de texto.
CTRL + A: Mover o cursor para o início da linha.
CTRL + E: Mover o cursor para o fim da linha.
CTRL + Y: Rolar a página para cima.
CTRL + V: Rolar a página para baixo.
CTRL + G: Exibir a janela de Ajuda com todos os comandos disponíveis.
CTRL + W: Pesquisar uma palavra específica no texto. Para pesquisar novamente a mesma frase, pressione ALT + W novamente.
SHIFT + seta: (direita, esquerda, para cima ou para baixo) para estender a seleção.
ALT + 6: cópia
CTRL + K: Recortar a linha atual.
CTRL + U: Colar o texto que foi recortado usando o CTRL + K ou ALT + 6.
CTRL + J: Justificar o parágrafo atual.
CTRL + C: Mostrar a posição atual do cursor no texto (linha/coluna/caractere).
CTRL + \: "replace" Pesquisa uma palavra para substitui-la.
CTRL + T: Executar o verificador ortográfico, se disponível.
CTRL + O: Salvar o arquivo.
CTRL + X: Sair do editor de texto Nano. Se houver alterações não salvas, o Nano solicitará uma confirmação para salvar.
Vamos combinar dois comandos no terminal usando uma tubulação pipe |.
Assim a listagem detalhada dos arquivos e diretórios é aberta no editor de texto Nano, isso te ajudar a ler saída de comandos muito longas sem precisar usar o less.
O sinal de menos - após o Nano indica que a entrada deve ser lida a partir da entrada padrão.
ls -l | nano -
vim
- Código:
vim ~/Documentos
- +informações:
- Vim é um editor de texto altamente configurável construído para tornar a criação e alteração de qualquer tipo de texto em algo primoroso.
Modos:
Modo de Comando: Pressione ESC para entrar neste modo.
Modo de Inserção: Pressione "i" para inserir texto no local do cursor.
Modo de Visualização: Pressione "v" para selecionar texto visualmente.
Movimentação:
Navegação por caracteres: Use as teclas de seta (←, →, ↑, ↓)
Navegação por palavras: Use "w" (próxima palavra) e "b" (palavra anterior).
Navegação por linhas: Use "gg" (início do arquivo) e "G" (fim do arquivo).
Edição:
Copiar: Posicione o cursor no início da seleção, pressione "v" para entrar no modo de seleção e mova o cursor para selecionar o texto. Pressione "y" para copiar.
Recortar: Selecione o texto (como descrito acima) e pressione "d" para recortar.
Colar: Posicione o cursor onde deseja colar o texto e pressione "p" para colar.
Desfazer/Refazer:
Desfazer: Pressione "u" para desfazer a última ação.
Refazer: Pressione "Ctrl + r" para refazer a ação desfeita anteriormente.
Salvar e Sair:
Salvar: No modo de Comando, digite ":w" e pressione Enter para salvar o arquivo.
Sair: No modo de Comando, digite ":q" e pressione Enter para sair do Vim.
Sair forçado: No modo de Comando, digite ":q!"
Salvar e Sair: No modo de Comando, digite ":wq" e pressione Enter para salvar e sair do Vim.
wc
- Código:
wc opções arquivo.txt
- +informações:
- O comando "wc" é uma abreviação para "word count", é usado para contar palavras, linhas e caracteres em um arquivo ou na entrada fornecida pelo usuário.
Algumas opções comuns do comando "wc" são:
-l ou --lines: Conta apenas o número de linhas.
-w ou --words: Conta apenas o número de palavras.
-c ou --bytes: Conta apenas o número de bytes.
-m ou --chars: Conta apenas o número de caracteres.
-L ou --max-line-length: Exibe o comprimento da linha mais longa.
Mostra o número de linhas, palavras e caracteres.
wc arquivo.txt
Essa é uma combinação de dois comandos no shell do Linux.
ls: Lista os arquivos e diretórios no diretório atual.
wc: Conta as linhas, palavras e bytes em um arquivo ou entrada, nesse caso a entrada foi fornecida através da saída do comando ls.
ls | wc
156 linhas 298 palavras 2960 bytes
Para mostrar somente os números das linhas:
ls | wc -l
touch
- Código:
touch nome_do_arquivo
- +informações:
- é usado para criar um arquivo de texto vazio, depois você pode abrir esse arquivo em um editor de texto ou outro software para torna-lo um script de algo.
Criar um novo arquivo vazio:
touch nome_do_arquivo
Para criar um arquivo oculto:
touch .nome_do_arquivo_oculto
Cria um novo arquivo vazio com nome aleatório:
touch ${RANDOM}.txt
Se o arquivo já existir, ele atualizar a data que o arquivo foi acesso pela última vez:
touch -a nome_do_arquivo
Definir uma data da última vez que esse arquivo foi acessado:
touch -t AAAAMMDDhhmm nome_do_arquivo
Criaremos uma árvore de diretórios com o "touch" e o "mkdir" um total de 8 pastas.
Essa estrutura contém as pastas: "diretorio", "subdir1", "subdir2", "subsubdir1" e "subsubdir2" cada subsubdir vai conter um arquivo vazio:
mkdir -p diretorio/{subdir1,subdir2}/{subsubdir1,subsubdir2} touch diretorio/{subdir1,subdir2}/{subsubdir1,subsubdir2}/arquivo.txt
Para criar vários arquivos de uma vez com o "touch" e o "for"
Isso criará cinco arquivos vazios chamados "arquivo1.txt", "arquivo2.txt", ..., "arquivo5.txt" no diretório atual.
for i in {1..5}; do touch arquivo$i.txt; done
Tem um comando chamado mktemp que é usado para criar arquivos ou diretórios temporários com nome aleatório para evitar colisões com outros arquivos temporários.
Esses arquivos temporários são gerados dentro do diretório /tmp
echo "Isso é um arquivo temporário" > "$(mktemp)"
É possível utilizar o comando mktemp para criar e atribuir um arquivo temporário à variável $tempfile. Podendo redirecionar a saída das operações subsequentes.
tempfile=$(mktemp); echo "Isso é um arquivo temporário2" > $tempfile
Ainda usando variáveis, vamos criar uma pasta temporária com um nome aleatório e atribui o caminho dessa pasta à variável $tempdir, depois criar um arquivo de texto temporário com um nome aleatório dentro da pasta aleatória.
tempdir=$(mktemp -d) && tempfile=$(mktemp --tmpdir=$tempdir) && echo "Isso é um arquivo temporário3" > "$tempfile"
nl
- Código:
nl arquivo.txt
- +informações:
- O comando nl (abreviação de "number lines") utilizada para numerar as linhas de um arquivo de texto.
Numerar todas as linhas de um arquivo de texto:
nl arquivo.txt
Numerar apenas as linhas não vazias de um arquivo de texto:
nl -b t arquivo.txt
Numerar todas as linhas de um arquivo de texto, especificando a largura do campo do número de linha:
nl -w 3 arquivo.txt
sed
- Código:
sed comando arquivo
- +informações:
- O sed (Stream Editor) é um editor de fluxo de texto que pode substituir, excluir ou transformar texto em um arquivo ou na saída padrão.
Para fins de teste, vou converter este texto de formato horizontal, como 'a b c', para o formato vertical.
sed 's/ /\n/g' $HOME/entrada.txt > $HOME/saida.txt
Alternativamente, você pode usar o comando echo como entrada de texto, para obter uma saída na própria tela do terminal.
echo "a b c" | sed 's/ /\n/g'
Aqui o comando sed vai adicionar aspas duplas em torno de cada palavra, estou usando um texto como entrada.txt
sed 's/\([^ ]\+\)/"\1"/g' $HOME/entrada.txt > 'com_aspas.txt'
ou imprima direto no terminal
echo "144 240 480 720 1080" | sed 's/\([^ ]\+\)/"\1"/g'
antes: 144 240 480 720 1080
depois: "144" "240" "480" "720" "1080"
Outra formas de se usar o comando sed
Enumerar as linhas: adicione números antes de cada palavra, você pode usar o comando nl junto com o sed. Aqui está um exemplo:
sed 's/ /\n/g' $HOME/arquivo.txt | nl -w1 -s'. '
ou imprima direto no terminal
echo "a b c" | sed 's/ /\n/g' | nl -w1 -s'. '
1. a
2. b
3. c
Outra variação: Em vez de substituir espaços por quebras de linha, você pode usar outro caractere como separador e também mantendo as palavras na horizontal. Por exemplo, para usar um hífen como separador.
sed 's/ /-/g' arquivo.txt
ou imprima direto no terminal
echo "a b c" | sed 's/ /-/g'
a-b-c
Vertical para horizontal com separação dos itens por vírgula com espaço.
O utilitário sed irá substituir todas as quebras de linha por uma vírgula seguida de um espaço.
sed ':a;N;$!ba;s/\n/, /g' $HOME/vertical.txt > vírgula.txt
ou imprima direto no terminal
echo "a
b
c" | sed ':a;N;$!ba;s/\n/, /g'
a, b, c
Substituir uma palavra por outra:
Suponha que você queira substituir a palavra "Aprovado" pela palavra "Reprovado" em um arquivo chamado "teste123.txt". O comando seria:
sed 's/Aprovado/Reprovado/g' $HOME/teste123.txt >> 'meunovo.txt'
ou imprima direto no terminal
echo "Aluno Aprovado" | sed 's/Aprovado/Reprovado/g'
Aluno Reprovado
Se você quiser excluir todas as linhas que contenham a palavra "Aprovado" em um arquivo chamado "teste123.txt", o comando seria:
sed '/Aprovado/d' $HOME/teste123.txt >> 'meunovo.txt'
ou imprima direto no terminal
echo "Aluno1
Aluno2 Aprovado
Aluno3" | sed '/Aprovado/d'
Aluno1
Aluno3
Vamos adicionar a palavra "Aprovado" no início de cada linha do arquivo "teste123.txt"
Se o arquivo 'meunovo.txt' já possuir texto, nenhuma informação será sobrescrita pois estamos usando >> que acrescenta a saída no final do arquivo existente.
sed 's/^/Aprovado /' $HOME/teste123.txt >> 'meunovo.txt'
ou imprima direto no terminal
echo "Aluno1
Aluno2
Aluno3" | sed 's/^/Aprovado /'
Aprovado Aluno1
Aprovado Aluno2
Aprovado Aluno3
Para identificar linhas que contenham os caracteres ▢ ou ●. Em seguida, ele remove todos os caracteres que estão antes desses marcadores, preservando apenas o conteúdo que aparece depois deles.
sed -E 's/.*([▢●]) (.*)/\2/g' arquivo_de_entrada.txt > arquivo_de_saida.txt
ou imprima direto no terminal
echo "Linux ▢ Melhor
Pior ● Linux" | sed -E 's/.*([▢●]) (.*)/\2/g'
Melhor
Linux
Usando sed, removi todas as linhas que não continham o padrão desejado, que é '+Fogo'. Em seguida, mantive apenas as ocorrências desse padrão em cada linha.
Para finalizar, eliminei as linhas vazias. Além disso, utilizei o comando wc para contar o número de ocorrências em vez de imprimir a saída padrão.
sed -e '/+Fogo/!d' -e 's/.*\(+Fogo\).*/\1/' -e '/^$/d' arquivo.txt | wc -l
Vamos excluir algumas linhas de um arquivo de texto, as linhas de 1 a 3994 serão apagadas.
Agora as linhas restantes, a partir da linha 3995, serão automaticamente movidas para o topo do arquivo.
a opção -i do sed realiza uma edição "in-place" no arquivo, o que significa que as alterações serão feitas diretamente no arquivo original.
sed -i '1,3994d' $HOME/teste123.txt
Para excluir três palavras diferente de todas as linhas do seu arquivo de texto.
sed -i '/palavra1\|palavra2\|palavra3/d' arquivo.txt
Excluir somente uma palavra do texto.
sed -i '/palavra1/d' arquivo.txt
Quando sua palavra contém caracteres como ponto . ou barra / é necessário adicionar uma barra invertida antes deles. Esse símbolo de barra invertida é conhecido como um caractere de escape e serve para indicar ao interpretador que o próximo símbolo não é um comando. Outros exemplos de caracteres que têm significados especiais e precisam ser escapados com uma barra invertida: * + ? [ ] ( ) { } | entre outros.
sed -i '/\.palavra/d' arquivo.txt
Como descrever múltiplas palavras contendo ponto:
sed -i '/\.php\|\.conf\|\.hook\|\.yml/d' arquivo.txt
Para exibir o conteúdo das linhas 100.000 até a linha 200.000 de um arquivo.
sed -n '100000,200000p' $HOME/teste123.txt
Este conjunto de comandos permite identificar as palavras mais frequentes em um arquivo de texto.
O comando funciona assim: lê um arquivo de texto, remove pontuações, quebra o texto em palavras, converte todas as letras para minúsculas,
conta a ocorrência de cada palavra, ordena as palavras por frequência e imprime as 50 palavras mais frequentes, juntamente com sua contagem.
cat arquivo.txt | sed 's/[.,:;?!]//g' | sed 's/ /\n/g' | awk '{print tolower($0)}' | grep -v '^$' | sort | uniq -c | sort -nr | head -n 50 | awk '{print $2, "=", $1}'- Detalhes do comando:
- cat arquivo.txt: Lê o conteúdo do arquivo chamado arquivo.txt.
sed 's/[.,:;?!]//g': Remove todas as ocorrências das pontuações especificadas (.,:;?!).
sed 's/ /\n/g': Substitui todos os espaços por quebras de linha, separando as palavras.
awk '{print tolower($0)}': Converte todas as letras em minúsculas.
grep -v '^$': Remove linhas em branco, caso existam.
sort: Ordena as palavras em ordem alfabética.
uniq -c: Conta a ocorrência de palavras únicas e imprime junto com a contagem.
sort -nr: Ordena a contagem em ordem decrescente.
head -n 50: Seleciona as 50 primeiras linhas (ou seja, as 50 palavras mais frequentes).
awk '{print $2, "=", $1}': Formata a saída para exibir a palavra, seguida de um sinal de igual e sua contagem.
tr
- Código:
tr opções conjunto_de_caracteres1 conjunto_de_caracteres2
- +informações:
- "tr" abreviação de "translate" ele é uma ferramenta de linha de comando utilizada para transformações simples de traduzir ou excluir caracteres em um fluxo de texto.
Ele é comumente usado para transformar caracteres em letras maiúsculas para minúsculas, converter espaços em tabulações, remover caracteres indesejados.
Ele não oferece a capacidade de usar expressões regulares complexas e abrangentes, como caracteres especiais, metacaracteres, classes de caracteres, quantificadores, âncoras, grupos de captura, como o sed e o awk fazem.
Converter letras minúsculas em maiúsculas:
tr '[:lower:]' '[:upper:]' < arquivo.txt >> maiúsculas.txt
ou imprima na tela do terminal
echo "texto" | tr '[:lower:]' '[:upper:]'
Converter letras maiúsculas em minúsculas:
tr '[:upper:]' '[:lower:]' < arquivo.txt >> minúsculas.txt
ou imprima na tela do terminal
echo "TEXTO" | tr '[:upper:]' '[:lower:]'
Substituir espaços por tabulações:
echo "linha 1 com espaços" | tr ' ' '\t'
Remover caracteres indesejados (por exemplo, remover todos os números):
tr -d '[:digit:]' < 'texto aqui.txt' >> 'sem dígitos.txt'
ou imprima na tela do terminal
echo "Texto com números 123" | tr -d '[:digit:]'
Transforme seu texto originalmente na vertical para um texto na horizontal:
tr '\n' ' ' < '/home/adr1/vertical.txt' >> 'vertical para horizontal.txt'
ou imprima na tela do terminal
echo -e "item1
item2
item3" | tr '\n' ' '
Transforme seu texto originalmente na vertical para um texto na horizontal, com os itens separados por vírgula: (seja o comando sed ele é melhor para isso)
tr '\n' ', ' < '/home/adr1/vertical.txt' >> 'vertical para horizontal.txt'
Transforme seu texto originalmente na horizontal para um texto na vertical:
tr ' ' '\n' < '/home/adr1/horizontal.txt' >> 'horizontal para vertical.txt'
Este comando lê o conteúdo do arquivo original, remove todas as aspas simples e duplas e salva o resultado no novo arquivo.
Atenção: esse comando pode estragar alguns caracteres especiais de seu texto,
como por exemplo este: e substitui-lo por esse � geralmente indicando um problema com a codificação ou uma incompatibilidade UTF-8 para ISO-8859-1.
e substitui-lo por esse � geralmente indicando um problema com a codificação ou uma incompatibilidade UTF-8 para ISO-8859-1.
tr -d "['\"“”]" < arquivo_original.txt > arquivo_sem_aspas.txt
Esse problema de codificação não acontecerá com esse outro comando:
tr -d "'\"" < arquivo_original.txt > arquivo_sem_aspas.txt
Este conjunto de comandos permite identificar as palavras mais frequentes em um arquivo de texto.
O comando funciona assim: lê um arquivo de texto, remove pontuações, quebra o texto em palavras, converte todas as letras para minúsculas,
conta a ocorrência de cada palavra, ordena as palavras por frequência e imprime as 50 palavras mais frequentes, juntamente com sua contagem.
cat arquivo.txt | tr -d '.,:;?!' | tr ' ' '\n' | tr '[:upper:]' '[:lower:]' | grep -v '^$' | sort | uniq -c | sort -nr | head -n 50 | awk '{print $2, "=", $1}'- Detalhes do comando:
- cat arquivo.txt: Lê o conteúdo do arquivo chamado arquivo.txt.
tr -d '.,:;?!': Remove todas as ocorrências das pontuações especificadas (.,:;?!).
tr ' ' '\n': Substitui todos os espaços por quebras de linha, separando as palavras.
tr '[:upper:]' '[:lower:]': Converte todas as letras maiúsculas em minúsculas, garantindo que a contagem de palavras seja case-insensitive.
grep -v '^$': Remove linhas em branco, caso existam.
sort: Ordena as palavras em ordem alfabética.
uniq -c: Conta a ocorrência de palavras únicas e imprime junto com a contagem.
sort -nr: Ordena a contagem em ordem decrescente.
head -n 50: Seleciona as 50 primeiras linhas (ou seja, as 50 palavras mais frequentes).
awk '{print $2, "=", $1}': Formata a saída para exibir a palavra, seguida de um sinal de igual e sua contagem.
sort uniq tr cut awk
- Código:
sort arquivo.txt
- +informações:
- O comando "sort" é uma ferramenta para ordenar linhas de texto em ordem alfabética ou numérica crescente.
Também oferece uma variedade de opções para personalizar o comportamento de ordenação, como ordenar em ordem decrescente, ignorar maiúsculas e minúsculas, definir delimitadores de campo.
Isso é particularmente útil para ordenar dados estruturados, como arquivos CSV ou logs com colunas de dados.
Ordenar um arquivo em ordem alfabética crescente:
sort arquivo.txt
Ordenar um arquivo em ordem alfabética decrescente:
sort -r arquivo.txt
Ordenar um arquivo em ordem alfabética, ignorando maiúsculas e minúsculas (palavras diferentes serão tratadas como iguais durante a ordenação.)
sort -f arquivo.txt
Ordenar um arquivo numérico em ordem crescente:
sort -n arquivo.txt
Se você tiver um arquivo de log onde as linhas também contem informações de data no formato "dd/mm/aaaa hh: mm:ss" e quiser ordenar essa linhas cronologicamente com base na data:
sort -t '/' -k3,3 -k2,2 -k1,1 -k4,4 -k5,5 -k6,6 log.txt- Criar um script para gerar datas:
- Copie para um editor de texto é salve como date.sh
depois execute no terminal ~/Documentos/date.sh- Código:
#!/bin/bash
# Função para gerar um número aleatório entre dois valores
random_number() {
shuf -i $1-$2 -n 1
}
# Função para gerar uma data aleatória
generate_random_date() {
local day=$(random_number 1 31)
local month=$(random_number 1 12)
local year=$(random_number 2000 2023)
local hour=$(random_number 0 23)
local minute=$(random_number 0 59)
local second=$(random_number 0 59)
printf "%02d/%02d/%04d %02d:%02d:%02d\n" $day $month $year $hour $minute $second
}
# Gerar 20 datas aleatórias
for ((i=1; i<=20; i++)); do
generate_random_date
done
Estamos utilizando o comando sort para ler o arquivo 'repetido' e assim agrupar as linhas duplicadas. Em seguida,
encaminhamos a saída para o comando uniq a fim de eliminar as linhas repetidas, e salvamos o resultado no arquivo chamado removido.txt.
sort $HOME/repetido | uniq > removido.txt
Além do comando sort, vamos utilizar outros três comandos: tr, sed e awk. A função principal deste comando será executada pelo sort,
com o objetivo de ordenar as palavras com base no seu comprimento. O arquivo de entrada contém uma lista de palavras na horizontal, separadas por espaços.
tr ' ' '\n' < $HOME/entrada.txt | awk '{print length, $0}' | sort -n | cut -d' ' -f2- | tr '\n' ' ' > $HOME/ordenado.txt
shuf
- Código:
shuf arquivo.txt
- +informações:
- O comando "shuf" é uma ferramenta usada para embaralhar, aleatorizar ou selecionar aleatoriamente linhas.
Pode ser útil quando você precisa embaralhar uma lista de nomes ou números, selecionar aleatoriamente um número, definir intervalos numéricos aleatórios.
Este comando irá gerar uma saída aleatória contendo um número entre 1 e 100.
-n especifica o número de linhas a serem exibidas, que neste caso é 1.
shuf -i 1-100 -n 1
Comando para sorteio de palavras:
primeiro criamos um array chamado "items" que contém as palavras desejadas.
Em seguida, usamos o comando "echo" para exibir todas as palavras do array em uma única linha, separadas por espaços.
Utilizamos o comando "tr" para substituir os espaços por quebras de linha, transformando cada palavra em uma linha separada.
Por fim, aplicamos o comando "shuf -n 1" para selecionar aleatoriamente uma linha (ou palavra) do resultado e imprimi-la.
items=("item1" "item2" "item3" "item4" "item5"); echo "${items[@]}" | tr ' ' '\n' | shuf -n 1
Embaralhar as linhas de um arquivo:
shuf arquivo.txt
Selecione 3 participantes aleatórios em seu arquivo de texto:
shuf -n 3 arquivo.txt
Imprime no terminal 10 dígitos aleatórios:
shuf -i 1-10
Embaralhar os elementos de uma lista separada por vírgula:
echo "item1,item2,item3,item4,item5" | tr ',' '\n' | shuf | tr '\n' ','
rev
- Código:
rev OPÇÕES ARQUIVO
- +informações:
- rev tem como função inverter a ordem dos caracteres
inverta uma palavra de trás para frente
echo "BSD é para quem ama o UNIX" | rev
saída: XINU o ama meuq arap é DSB
VOLTAR AO TOPO VOLTAR AO ÍNDICEÚltima edição por ADRIANNO em Sáb 27 Abr 2024, 9:33 am, editado 40 vez(es)
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:30 pm
por ADRIANNO Ter 07 Nov 2023, 1:30 pm
Última edição por ADRIANNO em Qua 15 Nov 2023, 4:52 pm, editado 3 vez(es)
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:30 pm
por ADRIANNO Ter 07 Nov 2023, 1:30 pm
VOLTAR AO ÍNDICE PRÓXIMA PÁGINAnohup
- Código:
nohup comando opções
- +informações:
- O comando nohup é usado para executar um programa de forma que ele não seja afetado quando o terminal que o iniciou é fechado.
Isso é útil quando você deseja iniciar um processo que deve continuar em execução mesmo depois de sair da sessão do terminal.
Pode ser qualquer comando que você normalmente executaria no terminal, como um programa ou script.
Digite o seguinte comando para iniciar o navegador Vivaldi usando nohup:
nohup vivaldi-stable &
o comando ls -l é executado em segundo plano e sua saída é redirecionada para o arquivo output.txt.
nohup ls -l > output.txt &
Executar um script em segundo plano com saída padrão e de erro redirecionadas para arquivos separados:
nohup ./meu_script.sh > output.txt 2> error.txt &
Executar um programa e ignorar a saída padrão e de erro:
nohup ./meu_programa > /dev/null 2>&1 &
top
- Código:
top OPÇÕES RECURSO
- +informações:
- O comando top é uma ferramenta para monitoramento do sistema, permite identificar processos que podem estar consumindo recursos excessivos.
Ele oferece uma visão abrangente em tempo real da utilização da CPU, memória e dos processos em execução no seu pc físico ou contêineres, como Docker ou Kubernetes.
Em sistemas onde o controle granular de recursos é importante para otimização e gerenciamento de tarefas.
Além disso, exibe informações, como a duração desde a última reinicialização do sistema, o status da memória (incluindo buffer, cache e uso total), a quantidade de memória swap em uso e livre, e o número de usuários atualmente conectados ao sistema.
Ele também apresenta estatísticas sobre o total de tarefas em execução, indicando quantas estão ativas, dormindo ou pausadas (sem consumir recursos momentaneamente). Tarefas zumbis, que são processos encerrados, mas cujos recursos ainda não foram liberados.
A média de carga do sistema é exibida, proporcionando um indicativo da carga média de trabalho que o sistema está enfrentando. Valores mais altos podem sinalizar uma possível sobrecarga do sistema.
Para encerrar o programa, basta pressionar a tecla q
Quando um programa é executado no sistema, ele é chamado de processo.
Para encerrar um processo usando o comando top, basta pressionar a tecla k durante o uso do comando.
vai abrir esse nova linha:
PID para sinal/terminação [pid padrão = 107306] DIGITE_O_ID_AQUI
vai solicitar que você defina o sinal a ser enviado para o processo. O sinal padrão é o sinal term que encerra com segurança, tem outros: sigkill para matar o processo na hora. sigint que envia um sinal de interrupção(Ctrl+C), Você pode simplesmente pressionar Enter para usar o sinal padrão.
Enviar sinal do pid 205348 [15/sigterm] DIGITE_O_SINAL
Uma breve explicação de alguns Sinais (Signals):
São notificações enviadas para processos pelo kernel do sistema operacional para indicar eventos como interrupções, erros ou solicitações do usuário.
Exemplos de sinais incluem SIGINT (gerado quando o usuário pressiona Ctrl+C) e SIGTERM (usado para solicitar a terminação de um processo).
HUP: Hang Up. Muitas vezes usado para recarregar configurações em processos em execução.
INT: Interrupt. Geralmente usado para interromper um processo em execução.
QUIT: Quit. Encerra um processo e produz informações de depuração.
KILL: Mata um processo imediatamente, sem dar a ele a chance de limpar ou salvar dados.
USR1: Sinal de usuário 1. Pode ser personalizado para qualquer finalidade específica pelo desenvolvedor do software.
USR2: Sinal de usuário 2. Similar ao USR1, mas para outro propósito personalizado.
TERM: Termination. Solicita que um processo se encerre de maneira limpa.
STOP: Para a execução de um processo. Pode ser retomada posteriormente com o sinal CONT.
CONT: Continuar a execução de um processo parado com o sinal STOP.
IO: Erro de E/S. Sinaliza problemas de entrada/saída em um processo.
Para ver uma lista de todos os sinais disponíveis que podem ser enviados:
kill -l
Os usuários comuns só podem enviar sinais para seus próprios processos. Para enviar sinais ao processo de outros usuários você deve ser um usuário root.
A distribuição percentual do uso da CPU, possui siglas:
"us" é o uso de CPU pelo usuário logado.
"sy" é o uso de CPU do sistema operacional.
"ni" é o uso de CPU com prioridade ajustada (nice).
"id" é o tempo em que a CPU está ociosa.
"wa" é o tempo em que a CPU está esperando (espera por operações de E/S).
"hi" é o tempo gasto em interrupções hardware.
"si" é o tempo gasto em interrupções software.
"st" é o tempo roubado de uma máquina virtual (caso esteja em uso).
Siglas para os status de processos:
R - Em execução (running)
S - Suspenso (suspended)
D - Em espera ininterrupta (uninterruptible sleep)
T - Parado (stopped)
Z - Zumbi (zombie)
I - Processo em execução com prioridade reduzida (idle)
W - Em espera no kernel
X - Processo morto
Para pesquisar o PID do processo pelo seu nome:
pgrep -f meu_programa
ou
ps aux | grep meu_programa
Para obter informações sobre o tempo de execução, mostrando a data e hora de início de um processo PID:
ps -p 131219 -o pid,etime,cmd
Versão minimalista
ps -o lstart= -p 131219
Para obter informações sobre um processo específico pelo seu PID, usando ps:
ps -p 38053 -o pid,ppid,user,cmd,%mem,rss,etime,start_time
pid: (38053) Exibe o PID (identificador de processo).
PPID: (32595) Exibe o PID do processo pai.
USER: (flyer) Exibe o nome do usuário que iniciou o processo.
CMD: (/usr/bin/python /usr/bin/vo...) Exibe o comando que está sendo executado pelo processo.
%MEM: (33.8) Exibe a porcentagem de memória física (RAM) utilizada pelo processo em relação à memória total do sistema.
RSS: (2736264) Exibe a quantidade de memória física que o processo está ocupando.
etime: (00:30) Exibe o tempo decorrido desde que o processo foi iniciado.
start_time: (12:15) Exibe o horário de início do processo.
Quanto ao comando que permite classificar as tarefas, ou seja, alterar a métrica usada para classificar os processos.
top -o FIELDNAME, substitua FIELDNAME por uma sigla que representa o nome do campo pelo qual você deseja classificar sua lista de processos.
abaixo vou mostrar alguns exemplos:
Observação: Se o seu sistema operacional estiver em inglês, utilize TIME+ em vez de TEMPO+
1) PID - Identificador do Processo (Process ID)
top -o PID
2) USER - Classifica os processos pelo nome do usuário.
top -o USUARIO
3) PR de Prioridade
top -o PR
4) NI - Valor de "nice": Um valor que afeta a prioridade do processo
top -o NI
5) VIRT - Memória Virtual: A quantidade de memória virtual usada pelo processo.
top -o VIRT
6) RES - Memória Residente: A quantidade de memória residente em RAM usada pelo processo.
top -o RES
7) SHR - Memória Compartilhada: A quantidade de memória compartilhada pelo processo.
top -o SHR
8) S - Estado do processo.
top -o S
9) %CPU - Uso de CPU: A porcentagem de uso da CPU pelo processo.
top -o %CPU
10)%MEM - Uso de Memória: A porcentagem de uso de memória pelo processo.
top -o %MEM
11) TEMPO+ - Tempo de CPU acumulado: O tempo total de CPU consumido pelo processo e seus processos filhos.
top -o TEMPO+
12) COMMAND - nome do programa
top -o COMANDO
EXTRA
Este comando classifica os processos com base na ordem de tempo que eles foram iniciados.
top -o ELAPSED- outras siglas:
- Essa lista foi produzida por esse comando top -O
PID - Identificador do Processo (Process ID): Um número único atribuído a cada processo em execução no sistema.
PPID - PID do Processo Pai (Parent Process ID): O PID do processo que iniciou ou criou o processo atual.
UID - Identificação do Usuário (User ID): O ID do usuário proprietário do processo.
RUID - UID Real (Real User ID): O UID real do usuário que iniciou o processo.
RUSER - Nome do Usuário Real: O nome do usuário real que iniciou o processo.
SUID - UID Efectivo (Effective User ID): O UID efetivo do usuário que iniciou o processo.
SUSER - Nome do Usuário Efectivo: O nome do usuário efetivo que iniciou o processo.
GID - Identificação do Grupo (Group ID): O ID do grupo ao qual o processo pertence.
GRUPO - Nome do Grupo: O nome do grupo ao qual o processo pertence.
PGRP - PID do Grupo de Processos (Process Group ID): O ID do grupo de processos ao qual o processo pertence.
TTY - Terminal associado ao processo: O terminal com o qual o processo está associado.
TPGID - PID do Grupo de Processos do Terminal (Terminal Process Group ID): O ID do grupo de processos do terminal ao qual o processo pertence.
SID - ID da Sessão (Session ID): O ID da sessão à qual o processo pertence.
PR - Prioridade: A prioridade do processo.
NI - Valor de "nice": Um valor que afeta a prioridade do processo (usuários comuns geralmente não podem aumentar a prioridade).
nTH - Número de Threads: O número de threads associadas ao processo.
P - de Processo: quando o campo processo aparece a letra: "R" é para processos em execução (running) e "S" para suspenso (suspended), veja outros tipo:- outros tipos de processos:
- D - Em espera ininterrupta (uninterruptible sleep): O processo está aguardando algum evento, como uma entrada/saída de disco, e não pode ser interrompido.
T - Parado (stopped): O processo foi temporariamente suspenso (por exemplo, pelo comando Ctrl+Z no terminal) e pode ser retomado posteriormente.
Z - Zumbi (zombie): O processo já terminou sua execução, mas ainda não foi removido completamente da tabela de processos. Esses processos são geralmente aguardando que seu pai os reconheça e recupere informações de saída.
I - Processo em execução com prioridade reduzida (idle): Essa é uma indicação de que o processo está executando com prioridade reduzida para evitar consumir muitos recursos do sistema.
W - Em espera no kernel: O processo está aguardando alguma ação no kernel.
X - Processo morto: Esse estado indica que o processo foi morto e está sendo removido do sistema.
< - Processo com prioridade negativa: Alguns sistemas usam "<" para indicar que o processo está em execução com prioridade negativa.
FIM
TEMPO - Tempo de CPU: O tempo total de CPU consumido pelo processo.
TEMPO+ - Tempo de CPU acumulado: O tempo total de CPU consumido pelo processo e seus processos filhos.
%MEM - Uso de Memória: A porcentagem de uso de memória pelo processo.
VIRT - Memória Virtual: A quantidade de memória virtual usada pelo processo.
SWAP - Uso de Memória Swap: A quantidade de memória swap usada pelo processo.
RES - Memória Residente: A quantidade de memória residente em RAM usada pelo processo.
CODE - Código do Programa: A quantidade de memória usada para armazenar código de programa.
DADO - Dados do Programa: A quantidade de memória usada para armazenar dados do programa.
SHR - Memória Compartilhada: A quantidade de memória compartilhada pelo processo.
S - Estado do processo: O estado atual do processo.
COMANDO - Comando ou nome do programa: O comando que iniciou o processo.
WCHAN - Esperando por: O que o processo está esperando (pode estar bloqueado esperando uma operação de E/S, por exemplo).
Flags - Sinalizadores do processo: Sinalizadores associados ao processo.
CGROUPS - Grupos de Controle: Informações sobre grupos de controle associados ao processo.
SUPGIDS - GIDs Suplementares: Grupos suplementares associados ao processo.
SUPGRPS - Grupos Suplementares: Grupos suplementares associados ao processo.
TGID - PID do Grupo de Threads (Thread Group ID): O ID do grupo de threads ao qual o processo pertence.
OOMa - Contagem de OOM em tempo real: Contagem de eventos de falta de memória em tempo real.
OOMs - Contagem de OOM em memória: Contagem de eventos de falta de memória relacionados à memória.
ENVIRON - Variáveis de ambiente: Informações sobre as variáveis de ambiente associadas ao processo.
vMj - Versão Principal da Memória Virtual: A versão principal da memória virtual.
vMn - Versão Menor da Memória Virtual: A versão menor da memória virtual.
USAD - Memória Usada: A quantidade de memória usada pelo processo.
nsIPC - Namespace IPC: Informações sobre o espaço de nomes IPC associado ao processo.
nsMNT - Namespace MNT: Informações sobre o espaço de nomes MNT associado ao processo.
nsNET - Namespace NET: Informações sobre o espaço de nomes NET associado ao processo.
nsPID - Namespace PID: Informações sobre o espaço de nomes PID associado ao processo.
nsUSER - Namespace USER: Informações sobre o espaço de nomes USER associado ao processo.
nsUTS - Namespace UTS: Informações sobre o espaço de nomes UTS associado ao processo.
LXC - LXC (Linux Containers): Informações sobre contêineres Linux associados ao processo.
RSan - Memória Residente Quadrante 1: Parte da memória residente em RAM do quadrante 1.
RSfd - Memória Residente Quadrante 3 e 4: Parte da memória residente em RAM dos quadrantes 3 e 4.
RSlk - Memória Residente Bloqueada: Parte da memória residente em RAM que não pode ser trocada.
RSsh - Memória Residente Compartilhada: Parte da memória residente em RAM que é compartilhada com outros processos.
CGNAME - Nome do Grupo de Controle: O nome do grupo de controle associado ao processo.
NU - Não Usado: Campo que não é usado.
LOGID - ID de Log: O ID de log associado ao processo.
EXE - Executável: O caminho para o executável associado ao processo.
RSS - Resident Set Size: O tamanho do conjunto residente, que é a quantidade de memória física usada pelo processo.
PSS - Proportional Set Size: O tamanho proporcional do conjunto, que é uma métrica de uso de memória.
PSan - Tamanho Proporcional Quadrante 1: Parte do tamanho proporcional associado ao quadrante 1.
PSfd - Tamanho Proporcional Quadrante 3 e 4: Parte do tamanho proporcional associado aos quadrantes 3 e 4.
PSsh - Tamanho Proporcional Memória Compartilhada: Parte do tamanho proporcional associado à memória compartilhada.
USS - Unique Set Size: O tamanho único do conjunto, que é uma métrica de uso de memória exclusiva.
ioR - Leituras de E/S: O número de operações de leitura de E/S.
ioRop - Leituras de E/S combinadas: O número combinado de operações de leitura de E/S.
ioW - Escritas de E/S: O número de operações de escrita de E/S.
ioWop - Escritas de E/S combinadas: O número combinado de operações de escrita de E/S.
AGID - ID do Grupo de Afinidade: O ID do grupo de afinidade associado ao processo.
AGNI - Número de Grupos de Afinidade: O número de grupos de afinidade associados ao processo.
STARTED - Hora de Início: O momento em que o processo foi iniciado.
ELAPSED - Tempo Decorrido: O tempo decorrido desde o início do processo.
%CUU - Uso de CPU do Usuário (%): A porcentagem de uso de CPU pelo usuário.
%CUC - Uso de CPU do Sistema (%): A porcentagem de uso de CPU pelo sistema.
nsCGROUP - Namespace CGROUP: Informações sobre o espaço de nomes CGROUP associado ao processo.
Ajuda do comando
top -h
-d 5 é uma opção que define um atraso de 5 segundos entre as atualizações da tela.
-b é para entrar no modo de lote (batch mode). Agora você pode usar o scroll do mouse.
top -b -d 5
Exibir na tela somente as informações detalhadas de um único processo:
top -p 2638
Ao usar a opção -i, você está instruindo a não exibir tarefas que não estão consumindo CPU no momento. (filtra as tarefas ociosas da lista)
top -i -p 2638
Exibir apenas processos de um usuário específico:
top -u root
Ao usar a opção -i, você está instruindo a não exibir tarefas que não estão consumindo CPU no momento. (filtra as tarefas ociosas da lista)
top -i -u root
(sistema multi-core) Mostra detalhes separados de consumo de cada núcleo da CPU.
top -1
Você pode usar o comando top junto com algumas opções para ordenar os processos pela quantidade de memória RAM que estão consumindo.
Definimos o top para trabalhar em modo batch, onde o número de atualizações que ele realizará sua varredura e uma única vez.
Estamos pegando apenas as primeiras 12 linhas da saída:
top -o %MEM -n 1 -b | head -n 12
Você pode usar um pipeline para filtrar apenas os nomes dos processos que mais estão consumindo memória.
top -o %MEM -n 1 -b | grep -E '^ *[0-9]+' | awk '{print $12}'
Você quer o nome do processo mais gastador de memória, então use:
top -o %MEM -n 1 -b | grep -E '^ *[0-9]+' | awk '{print $12}' | head -n 1
Para exibir apenas o número do PID (identificador do processo) que está consumindo mais memória RAM:
top -o %MEM -n 1 -b | grep -E '^ *[0-9]+' | awk '{print $1}' | head -n 1
Este comando lista todos os processos com o percentual de memória que estão utilizando.
Diferente do comando top que trunca os nomes dos processos em 8 dígitos para exibidos. Você pode usar o comando ps para exibir nomes de até 15 dígitos.
ps axo comm,%mem --sort=-%mem
Para filtrar somente a primeira saída:
ps axo comm,%mem --sort=-%mem | head -n 2 | tail -n 1
Para encerrar um processo pelo seu nome, você pode usar o comando killall:
killall firefox
Isso enviará um sinal de término suave para o Firefox, permitindo que ele finalize corretamente suas operações antes de encerrar.
pkill -15 firefox
a opção -9, envia um sinal SIGKILL, forçando o encerramento do processo.
pkill -9 firefox
Para encerrar um processo pelo seu número de PID
kill 1234
Isso encerrará imediatamente o processo com o PID 1234.
kill -9 1234
listar informações detalhadas sobre os processos em execução no sistema. A sigla "ps" significa (status do processo), e "aux" são opções específicas que controlam a saída do comando.
ps aux
é usada para listar os processos que contenham a palavra bash
ps aux | grep -i bash
O comando lsof significa list open files
É útil para diagnosticar problemas relacionados a arquivos, diretórios e sockets que estão sendo usados por processos em execução, vamos instala-lo:
sudo pacman -S lsof
Uma vez instalado, podemos trabalhar a saída desse comando com outros comando como o grep, para exibir apenas as linhas relevantes.
Por exemplo, se quisermos identificar quais processos estão interagindo com o diretório /home/adr1/windows_share, podemos usar o comando:
sudo lsof | grep /home/adr1/windows_share
Após localizar o PID (ID do processo) associado ao diretório, podemos encerrá-lo com o comando kill. Por exemplo, se o PID for 1691, podemos executar:
sudo kill -9 1691
O que realizamos com esses passos?
Identificamos um processo com base no diretório em que estava operando e, em seguida, encerramos esse processo.
Essa abordagem é útil para quando precisar desmontar um disco que está vinculado a um determinado diretório,
mas está recebendo uma mensagem de erro, dizendo que o dispositivo está ocupado.
Vou dar um exemplo prático, ao tentar desmontar um dispositivo montado, você pode receber o seguinte erro:
sudo umount -f ~/windows_share
umount: /home/adr1/windows_share: o alvo está ocupado.

xxd
- Código:
xxd OPÇÕES ARQUIVO
- +informações:
- Esse comando é encontrado em algum desses três utilitários bash-completion, Vim, gvim. Quem me deu essa informação foi o comando: pacman -F xxd
Com o xxd você converte dados binários em uma representação hexadecimal e vice-versa. man xxd para mais informações.
Converte um arquivo de texto para o formato binário, mostrando os bytes em grupos de 8 bits
xxd -b '/home/flyer/Documentos/texto.txt'
Converte o conteúdo digitado no echo para um formato binário,
em conjunto com o comando cut para exibir apenas uma parte específicas da saída, ocultando o prefixo no inicio de cada linha.
O texto passa por uma nova filtragem com o comando tr que irá excluir todos os caracteres que não são "0" ou "1" da saída.
echo -n "E=mc^2 - Albert Einstein" | xxd -b | cut -d ' ' -f 2- | tr -cd '01'
Resultando em uma saída limpa:
01000101 00111101 01101101 01100011 01011110 00110010
00100000 00101101 00100000 01000001 01101100 01100010
01100101 01110010 01110100 00100000 01000101 01101001
01101110 01110011 01110100 01100101 01101001 01101110
curl
- Código:
curl opções URL
- +informações:
- curl ou "Client URL" é uma ferramenta e biblioteca de linha de comando para transferir dados por meio de URLs. Existente desde 1998,
é utilizado para diversas finalidades, navegação web, download, desde transferência de arquivos, teste de conexões, preenchimento de campos (post), até interações complexas com servidores.
Suporta uma ampla variedade de protocolos como HTTP, HTTPS, FTP, FTPS e recursos, incluindo TLS, proxies, autenticação, retomada de transferência, compressão e outros.
É usado em scripts quanto em dispositivos como carros, TVs, smartphones e equipamentos médicos, sendo parte fundamental da Internet. Sendo um software de código aberto.
Selecione a ferramenta que melhor atenda às suas necessidades:
Há um comando semelhante ao curl chamado wget, que realiza downloads simples de arquivos da web. No entanto, o curl vai além, oferecendo recursos avançados, como interações com APIs, que o wget não possui.
Se planeja utilizar o curl para visualizar páginas web, opte pelo comando lynx: Este é um navegador de texto baseado em terminal sem renderização gráfica mas é capaz de exibir links.
Alguns parâmetros importantes:
-O: Salva os arquivos com seus nomes originais.
-L: Segue redirecionamentos se a página redirecionar para outra URL.
-s: significa "silencioso" "quiet" ele não exibirá mensagens de progresso ou mensagens de erro.
-k: Ignora erros de certificado SSL, o que é útil se o site usar HTTPS.
-I: realize apenas uma requisição dos cabeçalhos "HEAD" aquela sem um corpo, em vez de uma requisição completa de GET que é o padrão.
-p: Baixa todos os recursos da página, como imagens e folhas de estilo, mantendo a estrutura original de diretórios.
-e: Permite a manipulação do cabeçalho "Referer", que é utilizado para indicar a origem de um acesso a uma página da web. Essa prática pode ser usada para enganar a análise de tráfego, pois fornece informações enganosas ao servidor sobre a procedência do usuário. curl -e "https://www.google.com" https://exemplo.com
-X: Especifica o método HTTP a ser utilizado na solicitação. Por exemplo, -X POST indica que a solicitação deve ser um método POST.
-H: Permite adicionar cabeçalhos HTTP personalizados à solicitação. Por exemplo, -H "Content-Type: application/json" define o tipo de conteúdo como JSON.
-u: Permite especificar o nome de usuário e senha para autenticação básica HTTP. Por exemplo, -u user:password.
-i: Inclui os cabeçalhos da resposta na saída.
-T: --upload-file "file": Transfere um arquivo local para o destino.
-f: --fail, faz com que o curl falhe rapidamente e não exiba saída em caso de erros HTTP.
-v: --verbose, exibe informações detalhadas sobre a solicitação e resposta, incluindo os cabeçalhos.
-A ou --user-agent: Define o cabeçalho "User-Agent" na solicitação para simular um navegador web.
--cookie: Envia um cookie na solicitação. Pode ser usado para autenticação ou manter o estado da sessão.
--cookie-jar: Especifica um arquivo para armazenar cookies recebidos e usá-los em solicitações subsequentes.
--data: Envia dados no corpo da solicitação. Pode ser usado para enviar dados em uma solicitação POST.
--data-raw: Similar a --data, mas envia os dados exatamente como fornecidos, sem fazer qualquer codificação.
Para visualizar o conteúdo de uma página web em seu terminal:
curl https://flyer.forumeiro.com/t351-instalacao-arch-linux-bios-legacy-triple-boot-xfce-home-games
Baixar todo conteúdo da página e redirecioná-lo para um arquivo:
curl -o flyer.html https://flyer.forumeiro.com/t351-instalacao-arch-linux-bios-legacy-triple-boot-xfce-home-games
É equivalente ao comando anterior. É importante destacar que, ao abrir o arquivo de saída em um navegador, você visualizará o site completamente formatado.
Mas ao abrir o mesmo arquivo em um editor de texto, será possível visualizar o DOCTYPE html.
curl https://flyer.forumeiro.com/t351-instalacao-arch-linux-bios-legacy-triple-boot-xfce-home-games > flyer.html
Para limitar a velocidade de download em 56Kbps
curl --limit-rate 56k -o flyer.html https://flyer.forumeiro.com/t351-instalacao-arch-linux-bios-legacy-triple-boot-xfce-home-games
Para baixar um arquivo, estabelecendo um limite na taxa de transferência. Usaremos a opção --output para designar um nome a esse arquivo.
curl --limit-rate 56k --output archlinux-2023.11.01-x86_64.iso https://archlinux.c3sl.ufpr.br/iso/2023.11.01/archlinux-2023.11.01-x86_64.iso
Se não deseja especificar o nome do arquivo, use somente -O
curl --limit-rate 56k -O https://archlinux.c3sl.ufpr.br/iso/2023.11.01/archlinux-2023.11.01-x86_64.iso
Especifique o caminho onde vamos salvar o arquivo, para esse método é obrigatório definir um nome ao arquivo de saída.
curl --limit-rate 56k -o /media/archlinux-2023.11.01-x86_64.iso https://archlinux.c3sl.ufpr.br/iso/2023.11.01/archlinux-2023.11.01-x86_64.iso- outras ferramentas:
- Há vários gerenciadores de downloads disponíveis, e aqui estão alguns exemplos adicionais:
aria2, está no AUR com o nome de aria2cd, é um gerenciador de downloads eficiente:
aria2c --max-download-limit=56K https://flyer.forumeiro.com/t351-instalacao-arch-linux-bios-legacy-triple-boot-xfce-home-games
Baixe o conteúdo completo da página e direcione-o para um arquivo, nomeando-o com a data e hora de sua criação.
curl -o "$(date +\%d-\%m-\%Y_\%H:\%M:\%S).html" https://flyer.forumeiro.com/t351-instalacao-arch-linux-bios-legacy-triple-boot-xfce-home-games
Enviar uma solicitação HEAD (apenas cabeçalhos) a uma URL específica e obter informações sobre a resposta do servidor.
O cabeçalho da resposta inclui detalhes importantes sobre a página, como o código de status HTTP, data, tipo de conteúdo, cabeçalhos de segurança e outras informações relevantes como:
se e ou não um conteúdo que pode ser armazenado em cache, se o site é capaz ou não de reconhecer o seu navegador, muitas outras informações.
curl -I https://flyer.forumeiro.com/t351-instalacao-arch-linux-bios-legacy-triple-boot-xfce-home-games
-L é uma opção para seguir automaticamente os redirecionamentos do link. Quando você faz uma solicitação a uma URL, o servidor pode enviar uma resposta de redirecionamento que te jogará para outra URL.
curl -L https://flyer.forumeiro.com/t351-instalacao-arch-linux-bios-legacy-triple-boot-xfce-home-games
Para baixar todas as imagens de um site:
curl -s https://flyer.forumeiro.com/t351-instalacao-arch-linux-bios-legacy-triple-boot-xfce-home-games | grep -oE 'src="[^"]+"' | cut -d'"' -f2 | grep -iE '\.(jpg|png|gif|jpeg)$' | xargs -I {} curl -O {}
Para extrair todos os links listados em um site, você pode usar o comando curl em conjunto com outras ferramentas de linha de comando, como grep e awk.
Tudo é salvo em um arquivo de texto, vamos usar o comando sort -u para classifica as linhas e remove duplicatas, garantindo que cada link seja listado apenas uma vez.
url="https://flyer.forumeiro.com/t351-instalacao-arch-linux-bios-legacy-triple-boot-xfce-home-games" && curl -s "$url" | grep -oE 'href="([^"]*)"' | awk -F'"' '{print $2}' | awk -v base="$url" '{if($0 !~ /^http/) print base $0; else print $0}' | sort -u > links.txt
Transforme esse comando em um script com algumas praticidades; que usa um loop infinito para continuar solicitando novas URLs, é
Se preferir você pode abrir alguma URL da saída com um clique do mouse, vá em preferências no seu terminal xfce é marque a opção:
"Use o clique do meio do mouse para abrir urls" na aba Avançado.- Código:
#!/bin/bash
while true; do
read -p "Digite a URL: " input_url
# Executa o comando com a URL fornecida
url="$input_url" && curl -s "$url" | grep -oE 'href="([^"]*)"' | awk -F'"' '{print $2}' | awk -v base="$url" '{if($0 !~ /^http/) print base $0; else print $0}' | sort -u
# Imprime 1000 caracteres @ para sinalizar o fim do script
printf '%.0s@' {1..1000}; echo
done
Criando um script com curl.
guia rápido para criar um script
¹ Escreva o código do script em qualquer editor de texto.
² Salve o arquivo com nome.sh
³ Torne o script executável usando chmod +x
⁴ Execute o script no terminal '/home/flyer/nome.sh'
Este script em shell tem o propósito de executar scraping,
Download de todas as páginas de uma URL em formato .html:
Este script efetua o download de várias páginas de um blog, salvando cada uma no formato HTML.
Utiliza-se o utilitário curl para facilitar o download do conteúdo HTML, não se limitando apenas à página principal, mas também abrangendo outros subdiretórios do site.- abrir script:
- Código:
#!/bin/bash
base_url="https://blog.remontti.com.br/category/linux/tutoriais"
output_directory="/home/flyer/Nova pasta/5/"
page_number=1
while true; do
page_url="${base_url}/page/${page_number}/"
links=$(curl -s -L "$page_url" | grep -Eo 'https://blog.remontti.com.br/[0-9]+')
if [ -z "$links" ]; then
break
fi
while read -r link; do
article_content=$(curl -s -L "$link" | sed -n '/<article/,/<\/article>/p')
article_id=$(basename "$link")
echo -e "$article_content" > "${output_directory}${article_id}.html"
done <<< "$links"
page_number=$((page_number + 1))
done

Outro script²
Este script em shell realiza a extração do conteúdo de páginas da web e as arquiva em texto.
* O utilitário curl é empregado para baixar a página, usando a opção -L para seguir redirecionamentos se eles existirem.
* Em seguida, o conteúdo é processado por meio da ferramenta sed, que identifica e remove trechos delimitados por tags, preservando somente o texto.
* Além disso, o script prevê a mudança entre páginas, ex: https://site/page/2/ para https://site/page/3/. O número da página é inserido na URL utilizando a variável $page_number.
* Esse processo é mantido em um loop infinito até que seja interrompido manualmente.- abrir script:
- Código:
#!/bin/bash
base_url="https://martins2010.wordpress.com/"
output_file="/home/flyer/3/arquivo_de_saida.txt"
page_number=1
while true; do
page_url="${base_url}/page/${page_number}/"
text=$(curl -s -L "$page_url" | sed -n '/<p>/,/<\/p>/p' | sed 's/<[^>]*>//g')
if [ -z "$text" ]; then
break
fi
echo -e "\n\n[Page ${page_number}]\n\n$text" >> "$output_file"
page_number=$((page_number + 1))
done
Outro script³
* O comando realiza uma solicitação à URL fornecida para baixar as imagens do site.
* Ele busca por URLs que possuam as extensões .jpg, .png, .gif, .jpeg, uma vez que estamos interessados apenas nas imagens.
* Além disso, verifica se os novos arquivos tem o mesmo nome dos arquivos já existentes no diretório (renomeando, se necessário).- abrir script:
- Código:
curl -s https://flyer.forumeiro.com | grep -oE 'src="[^"]+"' | cut -d'"' -f2 | grep -iE '\.(jpg|png|gif|jpeg)$' | sed 's/^\/\/\|^\/[^/]/https:\/\/flyer.forumeiro.com&/' | while read -r url; do
filename=$(basename "$url")
counter=0
while [ -f "/home/flyer/Nova pasta/imagens/$filename" ]; do
counter=$((counter + 1))
filename="${counter}_${filename}"
done
curl -o "/home/flyer/Nova pasta/imagens/$filename" "$url"
done
Outro script⁴
* realiza o download de somente imagens.
* aumentei a amplitude dos formatos aceitos bmp tiff webp svg
* renomeia as imagens caso já existam no diretório de destino.
* para lidar com site que tem várias páginas numeradas, como https://www.profissionaisti.com.br/linux/page/2/ isso é chamado de paginação.
* no campo base_url= evite acrescentar uma barra no final da URL.- Abrir script:
- Código:
#!/bin/bash
base_url="https://www.profissionaisti.com.br/linux"
page_number=2
while true; do
page_url="${base_url}/page/${page_number}/"
image_urls=$(curl -s "$page_url" | grep -oE 'src="[^"]+"' | cut -d'"' -f2 | grep -iE '\.(jpg|png|gif|jpeg|bmp|tiff|webp|svg)$' | sed 's/^\/\/\|^\/[^/]/https:\/\/www.profissionaisti.com.br\/linux\//')
if [ -z "$image_urls" ]; then
break
fi
for url in $image_urls; do
filename=$(basename "$url")
counter=0
while [ -f "/home/flyer/Nova pasta/1/$filename" ]; do
counter=$((counter + 1))
filename="${counter}_${filename}"
done
curl -o "/home/flyer/Nova pasta/1/$filename" "$url"
done
page_number=$((page_number + 1))
done
Outro script⁵
Essa versão foi criada para funcionar em sites que geram imagens aleatórias, como por exemplo: https://randomwordgenerator.com/picture.php
* Acessa uma página que gera imagens de forma aleatória e as faz serem baixadas.
* Especifica o diretório de destino das imagens.
* Utiliza uma estrutura condicional if para criar um loop infinito; o loop é interrompido se não houver URLs com imagens.
* Renomeia as imagens para evitar reescrever os arquivos.
* Utiliza o comando curl -L para seguir redirecionamentos, o que é a parte essencial dessa abordagem.- abrir script:
- Código:
#!/bin/bash
base_url="https://www.generatormix.com/random-image-generator#google_vignette"
output_directory="/home/flyer/Nova pasta/1"
while true; do
page_url="$base_url"
image_urls=$(curl -s -L "$page_url" | grep -oE 'src="[^"]+"' | cut -d'"' -f2 | grep -iE '\.(jpg|png|gif|jpeg|bmp|tiff|webp|svg)$')
if [ -z "$image_urls" ]; then
break
fi
for url in $image_urls; do
filename=$(basename "$url")
counter=0
while [ -f "$output_directory/$filename" ]; do
counter=$((counter + 1))
filename="${counter}_${filename}"
done
curl -o "$output_directory/$filename" "$url"
done
done
Outro script⁶
Este script em Bash é projetado para baixar imagens de um site da web, seguindo links e navegando pelas páginas do site. /page/1/, /page/2/ etc.
Criando uma pasta para cada link e as preenchendo com as imagens extraídas.- +abrir script:
- Código:
#!/bin/bash
base_url="https://111111111111111111111111111111site"
output_directory="/home/flyer/Nova pasta/"
function process_page() {
local page_url="$1"
local safe_folder_name="${page_url//\/.-/}"
mkdir -p "${output_directory}/${safe_folder_name}"
image_urls=$(curl -s -L "$page_url" | grep -oE 'src="[^"]+"' | cut -d'"' -f2 | grep -iE '\.(jpg|png|gif|jpeg|bmp|tiff|webp|svg)$')
for url in $image_urls; do
filename=$(basename "$url")
curl -o "${output_directory}/${safe_folder_name}/${filename}" "$url"
done
}
function inspect_for_urls() {
local page="$1"
urls=$(curl -s -L "$page" | grep -oE 'href="[^"]+"' | cut -d'"' -f2 | grep 'https://111111111111111111111111111111site/')
for url in $urls; do
process_page "$url"
done
}
start_url="${base_url}/page/1/"
while true; do
inspect_for_urls "$start_url"
page_number=$((page_number + 1))
start_url="${base_url}/page/${page_number}/"
done
Outro script⁷
Este script⁷ é bastante semelhante ao script⁶. Pretendo aprimorá-lo para adicionar novas funcionalidades. Até o momento, ele é capaz de baixar imagens de um site da web,
seguindo os links encontrados nesse site. Considero este script incompleto devido à estrutura das pastas que ele cria, a qual ainda não estou satisfeito.- abrir script:
- Código:
#!/bin/bash
base_url="https://11111111111111site.com" # Substitua pelo URL de partida
output_directory="/home/flyer/Novapasta" # Substitua pelo diretório de saída desejado
function process_page() {
local page_url="$1"
local safe_folder_name="$(echo "$page_url" | sed 's/[^a-zA-Z0-9]/_/g')"
mkdir -p "${output_directory}/${safe_folder_name}"
image_urls=$(curl -s -L "$page_url" | grep -oE 'src="[^"]+"' | cut -d'"' -f2 | grep -iE '\.(jpg|png|gif|jpeg|bmp|tiff|webp|svg)$')
for url in $image_urls; do
filename=$(basename "$url")
curl -o "${output_directory}/${safe_folder_name}/${filename}" "$url"
done
}
function inspect_for_urls() {
local page="$1"
urls=$(curl -s -L "$page" | grep -oE 'href="[^"]+"' | cut -d'"' -f2 | grep '^https://11111111111111site.com')
for url in $urls; do
process_page "$url"
done
}
start_url="${base_url}"
while true; do
inspect_for_urls "$start_url"
# Você pode adicionar lógica adicional aqui, como um limite de páginas a serem visitadas.
# Aguarde alguns segundos antes de acessar a próxima página para não sobrecarregar o servidor.
sleep 5
# Implemente a lógica para encontrar a próxima página, por exemplo, seguindo links de paginação.
# Se não houver mais páginas para visitar, você pode sair do loop.
# break
done


cut
- Código:
cut opções delimitador campos arquivo
- +informações:
- O comando cut deriva da expressão recortar.
Ele é uma ferramenta criada para extrair campos ou colunas específicas de texto, usando separadores de campos (geralmente TAB).
Essa ferramenta é empregada para dividir ou segmentar informações de texto com base em colunas específicas.
Extrair os primeiros 10 caracteres de cada linha:
cut -c 1-10 $HOME/.bash_history
extrai colunas de um resultado de comando ls -l, que mostra arquivos e diretórios com detalhes.
O delimitador é configurado como espaço, separando as colunas. A extração foca na 11ª coluna (nome do arquivo) e na 4ª coluna (nome do proprietário).
ls -l | cut -d' ' -f 11,4
Isso extrairá o segundo campo da entrada, usando ; como delimitador personalizado
echo "nome;idade;cidade" | cut -d ';' -f 2
head
- Código:
head opções arquivo
- +informações:
- é usada para exibir as primeiras linhas de um arquivo ou fluxo de texto. Enquanto o comando tail exibe as últimas linhas, o head mostra as primeiras linhas de um arquivo.
Ele é frequentemente usado para visualizar rapidamente o início de arquivos de texto ou para inspecionar os cabeçalhos de arquivos, como arquivos CSV.
Aqui estão algumas opções comuns do comando head:
-n: Especifica o número de linhas a serem exibidas. Por exemplo, head -n 10 exibirá as últimas 10 linhas do arquivo. head -n 10 $HOME/.bash_history
-f: Monitora o arquivo em tempo real e exibe novas linhas conforme são adicionadas ao arquivo. head -f '/var/log/pacman.log'
-c: exibir os últimos 100 bytes desse arquivo: head -c 100 '/home/adr1/.bash_history'
-q: Imprime múltiplos arquivos. head -n 3 -q '/home/adr1/.bash_history' '/home/adr1/vírgula.txt'
-v: Mostra informações detalhadas sobre um ou mais arquivo, como seu nome. head -n 5 -v '/var/log/pacman.log' '/home/adr1/.bash_history'
Esse comando irá cortar as primeiras 100 linhas do arquivo de texto e enviá-las para a área de transferência, como um Ctrl+C / Ctrl+V, vou explicar o comando triplo:
O head irá exibir as primeiras 100 linhas do arquivo e o xclip enviará esse texto para a área de transferência. No fim o sed vai excluir as primeiras 100 linhas do arquivo.
head -n 100 arquivo.txt | xclip -selection clipboard && sed -i '1,100d' arquivo.txt
tail
- Código:
tail opções arquivo
- +informações:
- é usado para exibir as últimas linhas de um arquivo ou fluxo de texto, especialmente útil para monitorar alterações ou atualizações em arquivos.
Como os arquivos de logs em tempo real ou para visualizar seu histórico de comandos.
Aqui estão algumas opções comuns do comando tail:
-n: Especifica o número de linhas a serem exibidas. Por exemplo, tail -n 10 exibirá as últimas 10 linhas do arquivo. tail -n 10 $HOME/.bash_history
-f: Monitora o arquivo em tempo real e exibe novas linhas conforme são adicionadas ao arquivo. tail -f '/var/log/pacman.log'
-c: exibir os últimos 100 bytes desse arquivo: tail -c 100 '/home/adr1/.bash_history'
-q: Imprime múltiplos arquivos. tail -n 3 -q '/home/adr1/.bash_history' '/home/adr1/vírgula.txt'
-v: Mostra informações detalhadas sobre um ou mais arquivo, como seu nome. tail -n 5 -v '/var/log/pacman.log' '/home/adr1/.bash_history'
VOLTAR AO TOPO VOLTAR AO ÍNDICEÚltima edição por ADRIANNO em Dom 07 Abr 2024, 1:00 pm, editado 27 vez(es)
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:31 pm
por ADRIANNO Ter 07 Nov 2023, 1:31 pm
Última edição por ADRIANNO em Qua 15 Nov 2023, 4:54 pm, editado 1 vez(es)
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:31 pm
por ADRIANNO Ter 07 Nov 2023, 1:31 pm
VOLTAR AO ÍNDICE PRÓXIMA PÁGINA- Código:
x
- +informações:
- x
awk
- Código:
awk 'BEGIN { print "Olá Mundo" } #'
- +informações:
- Essa é uma linguagem interpretada orientada por dados, chamada AWK, Ela é especialmente útil para tarefas como:
filtrar, extrair, manipular, calcular e formatar informações em linhas de texto.
Filtrar: Permitindo selecionar apenas aquelas que atendem a determinadas condições.
Extrair: Permitindo que você capture e imprima apenas os campos desejados ou partes relevantes do texto.
Manipular: Incluindo operações matemáticas, formatação de saída, substituição de padrões e muito mais.
Calcular: Permitindo que você agregue informações, calcule estatísticas ou realize outras operações numéricas.
Formatar: Permitindo a criação de relatórios ou saídas bem estruturadas.
Essas informações de texto podem vir de várias fontes, entradas padrão (stdin) e saídas (stdout).
exemplos de linguagens interpretadas: AWK, Bash, Python, Ruby, PHP, JavaScript...
O AWK se difere das linguagens procedurais e compiladas por ser uma linguagem interpretada, exemplos de linguagens compiladas: C, C++, Rust, Go, Java, Fortran...
As linguagens compiladas, traduzem o código-fonte para código de máquina antes da sua execução.
Já o AWK não passa por um processo de compilação para código de máquina.
Quando um programa AWK é executado, cada linha do código é interpretada e executada sequencialmente pelo interpretador AWK.
Isso significa que as instruções são processadas conforme são encontradas, o código é interpretado sob demanda, sendo executado diretamente no terminal ou de um script.
O awk é amplamente utilizado para processamento de texto e análise de dados.
Sua integração com o shell é excelente, pois não entra em conflito com os caracteres especiais do shell.
Foi escrita em 1977 e lançada em 1987 pelos Laboratórios Bell e codificada no padrão POSIX Utilities de 1992.
Ela utiliza expressões regulares e arrays associativos; fazendo depuração do programa criado. Possui uma implementação GNU chamada gawk e é descrita no livro "Awk - Quarta Edição". As expressões regulares permitem buscar, corresponder e substituir padrões no texto. Os arrays permitem armazenar e acessar dados usando índices.
A linguagem também oferece funções embutidas para manipulação de strings, operações matemáticas e gerenciamento de data e hora.
, A vírgula é usada para separar expressões dentro do mesmo bloco de ações, que estão relacionadas e devem ser feitas juntas.
; O ponto e vírgula é usado para separar instruções independentes.
'' As aspas simples são usadas para delimitar.
{} As chaves indicam o início e o fim do bloco de ações.
// Qualquer texto entre as barras é tratado como um padrão a ser correspondido durante o processamento das linhas.
\ Barra invertida diz que o próximo caractere deve ser interpretado como um caractere literal e não um comando. Usado antes de um / ou .
$0 $1 $2 etc. $0 refere-se à linha inteira, enquanto $1, $2 ... referem-se aos demais campos da linha.
sub() Esta função substitui apenas a primeira ocorrência de um padrão em cada linha.
gsub() Esta função substitui todas as ocorrências de um padrão em cada linha.
BEGIN e END Indicam ações a serem executadas antes de processar o arquivo de entrada (no caso de BEGIN) e após o processamento do arquivo (no caso de END). Usamos BEGIN para inicializar variáveis e END para exibir resultados finais.
#############################################################################################################
Você pode abrir um arquivo de texto no AWK
awk '{print}' arquivo.txt
Imprima no terminal o conteúdo de dois arquivos de texto:
awk '{print}' arquivo1.txt arquivo2.txt
#############################################################################################################
Conte o número de linhas em um arquivo de texto.
awk 'END {print NR}' texto.txt
#############################################################################################################
Você também pode filtrar e manipular os dados dentro do arquivo de texto.
Vamos pedir ao AWK para imprimir apenas as linhas que contêm a palavra exemplo.
awk '/exemplo/' arquivo.txt
#############################################################################################################
O comando lê o arquivo entrada.txt e, para cada linha do arquivo irá adicionar o caractere /. É salvará em um novo arquivo chamado saida.txt
awk '{print "/" $0}' entrada.txt > saida.txt
Para excluir todos os caracteres . de todas as linhas.
awk '{gsub(/\./, ""); print}' entrada.txt > saida.txt
Para excluir o caractere -(hífen) e tudo que vem antes dele, em todas as linhas do texto.
Esse comando é útil quando o caractere está sempre aparecendo no mesmo local (segundo campo $2) de cada linha.
awk -F '-' '{print $2}' entrada.txt > saida.txt
Para excluir o caractere -(hífen) e tudo que vem antes dele, em todas as linhas do texto.
Esse comando é mais flexível e pode lidar com casos em que o caractere hífen está em diferentes posições da linha.
Usamos a função sub() para realizar uma substituição que vai do início da linha .* até o caractere desejado –
Estamos trocando essa parte do texto por uma string vazia, indicado pelas aspas duplas "" se um texto for inserido dentro das aspas, deixará de ser vazio.
awk '{sub(/.*-/, ""); print}' entrada.txt > saida.txt
Para excluir o sinal de ponto . e tudo que vem após esse sinal em cada linha.
Usamos a função sub() para realizar uma substituição que inicia no . até o fim da linha .*
Estamos trocando essa parte do texto por uma string vazia, indicado pelas aspas duplas "" se um texto for inserido dentro das aspas, deixará de ser vazio.
awk '{sub(/\..* /, ""); print}' entrada.txt > saida.txt
Para remover todas as linhas que contenham uma /, fazendo o AWK imprimir apenas as linhas que não contêm uma barra.
awk '!/\// {print}' entrada.txt > saida.txt
awk '!/flyer/ {print}' entrada.txt > saida.txt- +informações:
- Em expressões regulares no AWK, a barra / é usada para delimitar o padrão que estamos procurando.
Se quisermos que a própria barra / seja tratada como um caractere literal, e não como parte da sintaxe da expressão regular, precisamos escapá-la com uma barra invertida \.
#############################################################################################################
irá exibir apenas as linhas que contêm conteúdo, ignorando as linhas em branco do arquivo de texto.
cat arquivo.txt | awk NF
ou simplesmente:
awk NF arquivo.txt
#############################################################################################################
Veja como definir um separador de campo para separar os elementos dentro de uma linha em seu arquivo de texto. Vamos configurar o FS (Field Separator) no AWK.
Suponha que temos um arquivo.txt com o seguinte conteúdo:
Vamos processar esse arquivo.txt considerando : como separador para os campos e imprimir o nome e a idade das pessoas.
$1 é o primeiro campo da linha.
$2 é o segundo campo da linha.
awk -F: '{print "Nome:", $1, "\tIdade:", $2}' arquivo.txt
ou
awk 'BEGIN {FS=":"} {print "Nome:", $1, "\tIdade:", $2}' arquivo.txt
#############################################################################################################
Vamos usar o AWK para processar um arquivo do Linux /etc/passwd que contém as informações dos usuários do sistema.
Vamos definir um separador de campo, que será o sinal de : nossa intenção é imprimir os nomes do usuários com seus shells.
$1 Vamos pegar o primeiro campo da linha. (Nome do usuário.)
$NF Vamos pegar o último campo da linha. (Nome do shell do usuário.)
awk -F: '{print "Usuário:", $1, "\tShell:", $NF}' /etc/passwd
#############################################################################################################
Suponha que você tenha dois arquivos de texto chamados arquivo1.txt e arquivo2.txt
e você queirá imprimir no terminal o conteúdo de ambos, mas quer visualizar de uma forma personalizada, que mostre os números das linhas.
FILENAME é uma variável que contém o nome do arquivo, enquanto FNR guarda o número da linha, e $0 mostra o conteúdo da linha.
awk '{print "Arquivo:", FILENAME, "\tLinha:", FNR, "\tConteúdo:", $0}' arquivo1.txt arquivo2.txt
#############################################################################################################
o AWK pode escrever em arquivos de texto, seja um novo arquivo ou modificar um arquivo existente. Ele oferece recursos para manipular arquivos de entrada e saída.
Você pode usar o redirecionamento de saída padrão do AWK para escrever em um novo arquivo ou substituir o conteúdo de um arquivo existente.
awk 'BEGIN {print "Este é um exemplo de texto." > "saida.txt"}'
Vou criar um conteúdo de texto entrada.txt que contenha alguns nomes e idades, e então usarei o AWK para processá-lo e escrever o resultado no arquivo saida.txt.
awk '{print "Olá,", $1 ". Você tem", $2, "anos." > "saida.txt"}' entrada.txt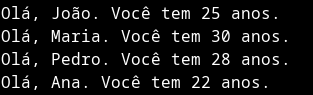
#############################################################################################################
Para demonstrar uma nova forma de usar o AWK:
Você pode executar os comandos diretamente no terminal ou optar por organizar esses comandos dentro de um script.
Nesse exemplo, o script chamado script.awk vai executar suas operações em um arquivo de texto.
awk -f script.awk arquivo.txt
#############################################################################################################
Vamos fazer o AWK ler o arquivo entrada.txt linha por linha e conta a frequência das palavras, e exibir essas contagens de palavras no terminal.
awk '{hist[$1]++} END {for (i in hist) print i ": " hist[i]}' entrada.txt- +informações:
- Esse comando tem duas partes:
1ª) Contagem de Frequência: {hist[$1]++}, é responsável por percorrer cada linha do arquivo de texto e contabilizar a frequência de ocorrência de cada valor no primeiro campo $1 da linha. Ele armazena essas contagens em um array chamado hist.
2ª) Impressão: END {for (i in hist) print i ": " hist[i]}, é executada após o processamento de todas as linhas do arquivo.
Ela itera sobre todas as chaves do array hist usando um laço for e imprime cada valor único seguido pelo número de vezes que esse valor apareceu no arquivo.
Exibindo para você nesse formato: "valor: frequência" em ordem arbitrária.
Agora que você tem os valores das frequências, você pode usá-los para criar um histograma. Um histograma é uma representação visual ou gráfico da distribuição de frequência dos valores.
Ao executar esse próximo comando em um arquivo de texto, você pode esperar obter como resultado a contagem total de ocorrências de uma determinada string no arquivo.
awk '{count += gsub("palavra_aqui", "")} END {print "palavra_aqui", count}' entrada.txt
é o mesmo comando, usando uma formatação de saída modificada:
awk '{count += gsub("palavra_aqui", "")} END {print "A palavra \"palavra_aqui\" aparece", count, "vezes."}' entrada.txt
Este conjunto de comandos vai demonstra como é mais complicado contas as palavras de um texto sem usar o sistema de colunas do AWK.
O comando funciona assim: lê um arquivo de texto, remove pontuações, quebra o texto em palavras, converte todas as letras para minúsculas,
conta a ocorrência de cada palavra, ordena as palavras por frequência e imprime as 50 palavras mais frequentes, juntamente com sua contagem.
awk '{gsub(/[.,:;?!]/,""); n=split($0, words, " "); for(i=1; i<=n; i++) { word = tolower(words[i]); if (word != "") { count[word]++; } }} END { for (word in count) { print count[word], word; }}' entrada.txt | sort -nr | head -n 50 | awk '{print $2, "=", $1}'- Detalhes do comando:
- gsub(/[.,:;?!]/,""): Remove todas as pontuações especificadas (.,:;?!).
n=split($0, words, " "): Divide cada linha em palavras e armazena no array words.
for(i=1; i<=n; i++) { word = tolower(words[i]): Percorre cada palavra no texto, convertendo-as para minúsculas e contabilizando suas ocorrências.
if (word != "") { count[word]++; }: Conta a ocorrência de cada palavra no array count.
END { for (word in count) { print count[word], word; }}': No final do processamento, itera sobre o array count e imprime a contagem e a palavra.
O resultado é então ordenado numericamente sort -nr, as 50 palavras mais comuns são selecionadas head -n 50,
e por fim, é feita a formatação da saída para imprimir a palavra seguida por sua contagem awk '{print $2, "=", $1}'
#############################################################################################################
Converte segundos em minutos, você pode incluir segundos fracionários, como 61, mas o resultado será arredondado.
echo "33999" | awk '{ minutos = int($1 / 60); print minutos " minutos" }'
Converte minutos em horas, mas usando o printf para formatar a saída nesse formato 4h24
echo "264" | awk '{printf "%dh%d\n", $1/60, $1%60}'
converte horas em minutos, as horas precisam estar nesse formato 11h59 ele aceita horas redondas nesse formato 8000h 800h 80h 8h
echo "4h24" | awk -F'h' '{ minutos = $1 * 60 + $2; print minutos }'
converte horas em minutos², É o mesmo comando acima, mas observe como incluir a palavra minutos na saída.
echo "4h24" | awk -F'h' '{ minutos = $1 * 60 + $2; printf "%d minutos\n", minutos }'
Converte dias em horas.
echo "3" | awk '{ horas = $1 * 24; print horas " horas" }'
Converte semanas em dias.
echo "40" | awk '{ dias = $1 * 7; print dias " dias" }'
Converte anos em dias.
echo "2" | awk '{ dias = $1 * 365; print dias " dias" }'
Converte anos em horas.
echo "2" | awk '{ horas = $1 * 365 * 24; print horas " horas" }'

Converte Celsius para Fahrenheit. O ponto de congelamento da água é de 32 graus Fahrenheit (°F).
echo "25" | awk '{ fahrenheit = ($1 * 9/5) + 32; print fahrenheit " °F" }'
Converte Fahrenheit em Celsius. multiplicamos por 5/9 e subtraimos 32.
echo "77" | awk '{ celsius = ($1 - 32) * 5/9; print celsius " °C" }'
Outra fórmula para converter temperaturas
Converte Pés para Metros. Metros vem do sistema métrico.
echo "328.08" | awk '{ metros = $1 / 3.2808; print metros " metros" }'
Converte Metros para Pés. Pés vem do sistema de unidades imperial.
echo "100" | awk '{ pes = $1 * 3.2808; print pes " pés" }'
Converte Quilômetros para Milhas. (Milhas por hora)
echo "145" | awk '{ milhas = $1 / 1.60934; print milhas " milhas" }'
Converte Milhas para Quilômetros. (Quilômetros por hora)
echo "80" | awk '{ quilometros = $1 * 1.60934; print quilometros " quilômetros" }'
Converte Reais para Dólares americanos.
echo "100" | awk '{ dolares = $1 / 5.18; printf "%.2f $\n", dolares }'
Converte Dólares americanos para Reais.
echo "100" | awk '{ reais = $1 * 5.18; printf "%.2f R$\n", reais }'
Converte Litros para Galões (EUA).
echo "10" | awk '{ galoes = $1 / 3.78541; print galoes " galões" }'
Converte Kg para Libras(lb).
echo "75" | awk '{ libras = $1 * 2.20462; print libras " libras" }'
Converte lb para quilogramas(kg).
echo "75" | awk '{ quilogramas = $1 * 0.4536; print quilogramas " Kg" }'
Converte cavalos-força (hp) em quilowatts (kW).
HP e KW são unidades de potência que representam a taxa na qual a energia é transferida para o motor. Para descrever a FORÇA (joules), que se refere às interações de contato entre dois corpos, utilizamos a Segunda Lei de Newton. É importante observar que Força ≠ Potência
echo "100" | awk '{ quilowatts = $1 * 0.7457; printf "%.2f quilowatts\n", quilowatts }'
Converte Bytes para Megabytes. envolve duas etapas:divide os bytes pelos kilobytes e, em seguida, divide os kilobytes pelos megabytes.
Os bytes precisam ser convertidos em kilobytes primeiro, para depois converte-los em megabytes.
1 kilobyte (KB) é igual a 1.024 bytes. 1 megabyte (MB) é igual a 1.024 kilobytes. 1 gigabyte (GB) é igual a 1.024 megabytes (MB). 1 terabyte (TB) é igual a 1.024 gigabytes
echo "1048576" | awk '{ megabytes = $1 / 1024 / 1024; print megabytes " MB" }'
#############################################################################################################
Irá analisar o arquivo "lista de jogos.txt" e imprimir linhas inteiras que contenham a palavra "DLC".
awk '/DLC/' '/home/adr1/Documentos/lista de jogos.txt' >> 'Minhas DLCs.txt'
#############################################################################################################
Remover palavras repetidas em um texto.
awk 'BEGIN{RS=" ";ORS=" "}{ if (!seen[$0]++) print }' 'arquivo aqui.txt' >> repetidas.txt
ou imprima na tela do terminal
echo "a a b b c" | awk 'BEGIN{RS=" ";ORS=" "}{ if (!seen[$0]++) print }'
As aspas fazem com que o shell trate os próximos caracteres como um único argumento.
BEGIN{RS=" ";ORS=" "} Define a variável RS (Record Separator) como um espaço em branco, ou seja, cada palavra será tratada como um registro separado.
Além disso, define a variável ORS (Output Record Separator) como um espaço em branco, para que a saída seja impressa na mesma linha.
{ if (!seen[$0]++) print } Para cada palavra encontrada, verifica se ela já foi vista antes. Se a palavra ainda não foi vista então a palavra é impressa.
#############################################################################################################
O seguinte comando irá analisar um texto que contém uma lista de jogos, incluindo informações como preço, data da compra, idioma e sistema operacional.
Vamos instruir o AWK a extrair apenas os preços dos jogos desse texto.
awk -F 'R\\$=' '{ if ($2 != "") { sub(/ .*/, "", $2); printf "%s\n", $2 } }' '/home/adr1/Documentos/lista de jogos.txt' >> preços.txt- +informações:
- -F 'R\\$=' Essa opção busca esse campo R$= em cada linha
'{ if ($2 != "") abrimos uma chave para delimitar onde vamos trabalhar, o $2 diz que vamos extrai os valores numéricos após a sequência R$=
{ sub(/ .*/, "", $2) abrimos outra chave para uma nova tarefa, sub() é usada para substituir uma parte de uma string por outra string, ele ira copiar o próximo campo depois de R$= (incluindo letras, números, símbolos etc.).
printf "%s\n", $2 } }' essa função imprime o valor que apareceram após o R$= e adiciona uma quebra de linha "%s\n"
~
Uma versão diferente do código anterior, para ignorarmos palavras como COMPRAR e FREE depois do R$=
awk -F 'R\\$=' '{ if ($2 != "") { sub(/ .*/, "", $2); gsub(/(COMPRAR|FREE)/, "", $2); if ($2 != "") printf "%s\n", $2 } }' '/home/adr1/Documentos/lista de jogos.txt' >> preços2.txt
A função gsub() substitui todas as ocorrências dessas palavras.
~
Continuando com esse exemplo, se você deseja imprimir na tela uma soma do total desses preços:
awk -F 'R\\$=' '{ if ($2 != "") { sub(/ .*/, "", $2); gsub(/(COMPRAR|FREE)/, "", $2); gsub(/,/, ".", $2); if ($2 != "") total += $2 } } END { printf "Total: R$=%.2f\n", total }' '/home/adr1/Documentos/lista de jogos.txt'
gsub(/,/, ".", $2) aqui vamos substituir as vírgulas 1,23 por pontos 1.23. Isso permite que o valor seja interpretado corretamente com duas casas decimais.(IMPORTANTE)
~
Uma forma diferente de trabalhar com o AWK é criar um script, salve esse código em um editor de texto com a extensão soma.awk
- CTRL+C:
- Código:
#!/bin/awk -f
BEGIN {
FS = "R\\$="
total = 0
}
{
if ($2 != "") {
sub(/ .*/, "", $2)
gsub(/(COMPRAR|FREE)/, "", $2)
gsub(/,/, ".", $2)
if ($2 != "") total += $2
}
}
END {
printf "Total: R$=%.2f\n", total
}
awk -f '/home/adr1/Documentos/soma.awk' '/home/adr1/Documentos/lista de jogos.txt'
- TEXTO de exemplo:
- 1-(4,9 GiB) Baldur's Gate: Enhanced Edition 06-05-21 R$=7,39 ⮝
(DLC) Siege of Dragonspear 23-07-21 R$=7,39
(DLC) Faces of Good and Evil 23-07-21 R$=1,09
2-(2,8 GiB) Icewind Dale: Enhanced Edition 06-05-21 R$=7,39 ⮝
3-(?,? GiB) The Witcher: Enhanced Edition 18-05-21 R$=2,39 ❖
4-(?,? GiB) The Witcher 2: Assassins of Kings Enhanced Edition 18-05-21 R$=5,49 ⮝
5-(14,5 GiB) Tyranny - Standard Edition 21-05-21 R$=28,99 ⮝
(DLC) Tales from the Tiers 27-11-21 R$=6,99
(DLC) Bastard's Wound 28-01-22 R$=14,00
6-(23,5 GiB) Pillars of Eternity: Definitive Edition 21-05-21 R$=29,99 ⮝
7-(9,7 GiB) Divinity: Original Sin - Enhanced Edition 13-06-21 R$=25,59 ⮝
8-(7,7 GiB) Neverwinter Nights: Enhanced Edition 13-06-21 R$=9,49 ⮝
(DLC) Infinite Dungeons 20-08-21 R$=0,99
(DLC) Dark Dreams of Furiae 20-08-21 R$=2,19
(DLC) Pirates of the Sword Coast 29-10-21 R$=1,09
(DLC) Tyrants of the Moonsea 29-10-21 R$=4,09
(DLC) Wyvern Crown of Cormyr 29-10-21 R$=1,09
(DLC) Darkness Over Daggerford 29-10-21 R$=4,09
9-(49,7 GiB) Pillars of Eternity II: Deadfire 29-06-21 R$=36,99 ⮝
(DLC) The Forgotten Sanctum 29-06-21 R$=9,19
(DLC) The Beast of Winter 29-06-21 R$=9,29
(DLC) Seeker, Slayer, Survivor 26-11-21 R$=4,69
10-(?,? GiB) Baldur's Gate II: Enhanced Edition 23-07-21 R$=7,39 ⮝
11-(0,6 GiB) Stardew Valley 03-08-21 R$=14,99 ⮝
12-(0,2 GiB) Democracy 3 09-10-21 R$=22,99 ⮝
(DLC) Social Engineering R$=5,29
(DLC) Extremism R$=5,29
(DLC) Clones and Drones R$=5,29
(DLC) Electioneering R$=9,89
13-(0,6 GiB) Balrum 28-10-21 R$=7,69 ⮝
14-(0,2 GiB) Din's Curse 31-10-21 R$=5,00 ⮝
(DLC) Din's Curse: Demon War 31-10-21 R$=2,49
15-(0,4 GiB) Din's Legacy 31-10-21 R$=19,00 ⮝
16-(0,1 GiB) Depths of Peril 31-10-21 R$=5,00 ⮝
17-(37,5 GiB) Pathfinder: Kingmaker - Imperial Edition Bundle 31-10-21 R$=32,79 ⮝
(DLC) Varnhold's Lot (preço incluso)
(DLC) Bloody Mess 30-11-21 (FREE)
(DLC) In-game player's portraits (preço incluso)
(DLC) Beneath The Stolen Lands (preço incluso)
(DLC) Arcane Unleashed 30-11-21 (FREE)
(DLC) Premium Digital Copy (preço incluso)
(DLC) In-Game Pet - Red Panda (preço incluso)
(DLC) The Wildcards (preço incluso)
18-(1,0 GiB) Sheltered 26-11-21 R$=6,99 ⮝
19-(5,1 GiB) Mount & Blade: Warband 26-11-21 R$=7,49 ⮝
(DLC) Viking Conquest Reforged Edition 27-11-21 R$=7,49
(DLC) Napoleonic Wars 27-11-21 R$=6,99
20-(6,0 GiB) Dex 29-11-21 R$=3,69 ⮝
21-(0,3 GiB) Zombasite 22-12-21 R$=9,29 ⮝
(DLC) Orc Schism R$=5,19
22-(0,8 GiB) Nebuchadnezzar 22-12-21 R$=24,69 ⮝
23-(0,04 GiB) PULSTAR 22-12-21 R$=2,99 ⮝
24-(0,8 GiB) Diablo + Hellfire 30-12-21 R$=45,29 ❖
25-(4,7 GiB) Train Fever 15-02-22 R$=5,59
26-(0,1 GiB) THE KING OF FIGHTERS 2002 15-02-22 R$=2,99
27-(3,6 GiB) Grim Dawn 20-02-22 R$=9,19 ❖
(DLC) Ashes of Malmouth 17-06-23 R$=22,69
(DLC) Forgotten Gods 17-06-23 R$=20,23
28-(1,3 GiB) Fell Seal: Arbiter's Mark 20-02-22 R$=24,99
(DLC) Missions and Monsters 20-02-22 R$=17,49
29-(1,2 GiB) Dead Cells 02-04-22 R$=33,29 ⮝
(DLC) The Bad Seed R$=7,59
(DLC) Rise of the Giant R$=FREE
(DLC) Fatal Falls R$=7,59
(DLC) The Queen and the Sea (FALTA)
30-(2,2 GiB) The Signal From Tölva 20-02-22 R$=9,29 ⮝
31-(1,9 GiB) Gurumin: A Monstrous Adventure 12-04-22 R$=2,99 ❖
32-(1,5 GiB) Beholder 14-04-22 R$=2,99 ⮝
33-(4,5 GiB) Project Zomboid 14-04-22 R$=25,49 ⮝
34-(0,6 GiB) Torchlight 16-04-22 R$=12,49 ❖
35-(4,3 GiB) Sid Meier's Civilization IV: The Complete Edition 18-05-22 R$=11,29 ❖
36-(8,8 GiB) Fallout 3: Game of the Year Edition 22-05-22 R$=9,19 ❖
37-(0,7 GiB) FATE 22-05-22 R$=19,89 ❖
(1,0 GiB) FATE: The Cursed King ❖
(1,0 GiB) FATE: The Traitor Soul ❖
(0,8 GiB) FATE: Undiscovered Realms ❖
38-(30,8 GiB) Warhammer: Chaosbane Slayer Edition 24-05-22 R$=13,59 ❖
39-(10,4 GiB) Warhammer 40,000: Mechanicus 05-06-22 R$=11,79 ⮝
(DLC) Mechanicus - Heretek R$=8,49
40-(1,8 GiB) Warhammer 40,000: Fire Warrior 05-06-22 R$=5,79 ❖
41-(?,? GiB) Exiled Kingdoms 05-06-22 R$=13,29 ⮝
42-(1,8 GiB) Rise of Industry 05-06-22 R$=14,79 ⮝
(DLC) 2130 (FALTA)
43-(5,4 GiB) Hellpoint 08-06-22 R$=26,39 ⮝
44-(0,1 GiB) Rise of the Triad: Dark War 08-06-22 R$=1,99 pt ⮝
(DLC) Trains R$=COMPRAR
45-(0,6 GiB) Don't Starve 23-02-23 R$=5,19 EN ⮝
(DLC) Reign of Giants 22-03-23 R$=2,59
(DLC) Shipwrecked R$=COMPRAR
(DLC) Hamlet R$=COMPRAR
46-(0,6 GiB) Legend of Keepers: Career of a Dungeon Manager 23-02-23 R$=9,99 pt ⮝
(DLC) Return of the Goddess R$=6,19
(DLC) Feed the Troll R$=6,19
(DLC) Soul Smugglers R$=6,19
47-(1,7 GiB) Planet Nomads 23-02-23 R$=18,50 pt ⮝
48-(4,1 GiB) Victor Vran 23-02-23 R$=9,99 pt ⮝
(DLC) Fractured Worlds R$=4,79
(DLC) Motörhead - Through the Ages R$=4,79
49-(0,02 GiB) Cryptark 23-02-23 R$=6,99 EN ⮝
50-(0,4 GiB) MachiaVillain 20-03-23 R$=3,69 PT ⮝
51-(7,0 GiB) Tomb Raider: Underworld 22-03-23 R$=1,89 EN ❖
52-(0,2 GiB) Hero of the Kingdom 14-04-23 R$=2,39 PT ❖
53-(0,9 GiB) Heroes of Might and Magic 3: Complete 17-06-23 R$=5,00 EN ❖
3: Complete 17-06-23 R$=5,00 EN ❖
54-(4,3 GiB) Two Worlds Epic Edition 17-06-23 R$=5,99 EN ⮝
55-(0,7 GiB) Lula: The Sexy Empire 17-06-23 R$=2,79 EN ❖
56-(8,2 GiB) Ancestors: The Humankind Odyssey R$=37,49 17-06-23 PT ❖
57-(0,4 GiB) Caesar 3 R$=7,79 23-06-23 EN ❖
58-(1,3 GiB) Caesar IV R$=7,19 23-06-23 EN ❖
59-(0,3 GiB) Hero of the Kingdom II R$=3,99 23-06-23 PT ⮝
60-(0,3 GiB) Hero of the Kingdom III R$=4,19 23-06-23 PT ⮝
61-(0,02 GiB) Mortal Kombat 1+2+3 R$=2,99 23-06-23 EN ❖
62-(20,0 GiB) Dragon's Dogma: Dark Arisen R$=11,99 23-06-23 EN ❖
63-(1,2 GiB) Ascension to the Throne R$=2,09 23-06-23 EN ❖
64-(0,2 GiB) 9th Dawn III R$=13,99 23-06-23 EN ⮝
#############################################################################################################













OpenSSL
- Código:
openssl subcomando opções argumentos
- +informações:
- é uma biblioteca de criptografia de código aberto, fornece uma variedade de algoritmos criptográficos SHA-256 e MD5 e recursos para gerar chaves, assinar e verificar certificados digitais e muito mais.
Para gerar uma senha aleatória. rand é a subcomando para gerar números aleatórios.
openssl rand -base64 12
gera uma senha no formato hexadecimal.
openssl rand -hex 12
Gerar uma senha com caracteres alfanuméricos e símbolos:
openssl rand -base64 20 | tr -d '/+=' | head -c 20
for
- Código:
for i in valor1 valor2 ... do comandos done
- +informações:
- O comando "for" é um recurso que cria loops, repetindo um conjunto de comandos para um conjunto de valores específicos.
Ele é usado para automatizar tarefas e executar comandos em várias iterações. for é usado quando se tem uma lista de valores predefinidos ou quando se deseja iterar sobre os elementos de uma lista.
Durante cada iteração do loop, os comandos especificados entre "do" e "done" são executados. A variável assume o valor atual da lista e pode ser usada nos comandos dentro do loop.
for i in 1 2 3 4 5; do echo "Valor: $i"; done
o bloco de comandos será executado cinco vezes, uma para cada valor na lista 1, 2, 3, 4, 5. A cada iteração, a variável i assumirá um valor da lista, e a mensagem "Valor: X" será exibida, onde X é o valor atual de i.
while
- Código:
while condição; do comando; done
- +informações:
- Ele é usado principalmente em scripts e programas para criar loops ou repetições.
é usado quando se tem uma condição que deve ser verificada antes de cada iteração do loop. Enquanto a condição for verdadeira, o bloco de comandos será executado.
Diferentemente do comando for, o while não requer uma lista de valores predefinidos. Em vez disso, ele permite a execução repetida de um bloco de comandos com base em uma condição que pode ser alterada durante a execução do loop. O bloco de comandos será executado até que a condição se torne falsa.
Exemplo de loop de repetição infinita. (Ctrl+C) para parar o loop
while true; do echo "Loop infinito"; done
Nesse outro exemplo, o loop é executado enquanto o valor da variável count for menor ou igual a 5. A cada repetição, a mensagem "Contagem: X" é exibida, onde X é o valor atual de count.
Em seguida, o script aguarda 1 segundo usando o comando sleep e incrementa o valor de count. Esse loop será executado cinco vezes, exibindo a contagem de 1 a 5.
count=1; while [ $count -le 5 ]; do echo "Contagem: $count"; sleep 1; count=$((count+1)); done
Nesse outro exemplo, vamos criar um script propriamente:
Este é um exemplo simples; adicione mais complexidade às strings para adaptá-las às suas necessidades.
O objetivo deste script é processar um texto, inserindo prefixo e sufixo em todas as linhas.
Vamos processar uma lista de nomes, eles são autores de livros sobre Linux.
Christopher Negus
Mark Sobell
Evi Nemeth
Nosso script irá trabalhar o texto para obter a seguinte saída:
"Christopher Negus" download PDF
"Mark Sobell" download PDF
"Evi Nemeth" download PDF
1- Vamos começar criando o script. Em qualquer editor de texto, cole este texto e salve-o como add_prefix_suffix.sh- Código:
#!/bin/bash
prefixo='"'
sufixo='" download PDF'
while IFS= read -r linha; do
texto_com_prefixo_sufixo="$prefixo$linha$sufixo"
echo "$texto_com_prefixo_sufixo"
done
O interpretador de shell usará o Bash.
Definimos duas variáveis chamadas prefixo e sufixo que armazenam strings.
Que inicia um loop while, até que não haja mais linhas para ler.
IFS= desativa a divisão de palavras, garantindo que espaços em branco no início ou final da linha não sejam removidos.
read -r evita que as sequências de escape sejam interpretadas.
Criamos o formato da variável, e chamamos de texto_com_prefixo_sufixo
No fim usamos o comando echo para exibir o conteúdo da variável.
Como usar esse script?
2- Torne o arquivo executável:
chmod +x '/home/flyer/Documentos/add_prefix_suffix.sh'
3- Agora você pode usar o script da seguinte maneira:
echo "Christopher Negus
Mark Sobell
Evi Nemeth" | '/home/flyer/Documentos/add_prefix_suffix.sh'
sleep
- Código:
comando | sleep 1m
- +informações:
- Não tem haver com desligar ou hibernar o computador.
O comando sleep é usado para suspender a execução de um processo por um determinado período de tempo. Ele é útil quando você deseja adicionar um atraso ou pausa em um script ou comando.
milissegundos(500ms), segundos(1), minutos(1m), horas(1h) aguardando um determinado intervalo de tempo entre a execução de comandos, ou para simular atrasos em processos de teste e depuração.
ping -c 5 google.com | while read line; do echo $line; sleep 4; done
ping -c 5 google.com: comando que ping 5 pacotes no host.
| como pipe, redirecionamos a saída do ping para o próximo comando.
while read line; do ... done Este é um loop while. O valor lido é armazenado na variável line.
echo $line: Este comando echo exibe o valor da variável line, ou seja, imprime cada linha recebida do comando ping.
sleep 1: Este comando vai pausar a execução do ping por 4 segundo antes de continuar para a próxima iteração do loop. Isso cria um atraso de 4 segundo entre cada linha impressa.
echo "Iniciando o processamento..."; sleep 5 echo; "Processamento concluído."
o script exibe a mensagem "Iniciando o processamento..." e, em seguida, pausa a execução por 5 segundos usando o comando sleep 5. Após a pausa, o script imprime a mensagem "Processamento concluído.".
tee
- Código:
comando | tee arquivo
- +informações:
- é usado para redirecionar a saída de um comando para um arquivo e também para exibir essa saída no terminal ao mesmo tempo.
O comando tee e o operador >> têm propósitos diferentes, mas quase sempre estão trabalhando juntos, vamos entender esses dois:
tee permite que você veja a saída de um comando ao mesmo tempo em que você o envia para um arquivo.
O operador >> não mostra a saída na tela, ele só redireciona.
a saída do comando ls -l será exibida no terminal e também será gravada no arquivo "arquivo.txt".
ls -l | tee arquivo.txt
a frase "Nova linha" será adicionada ao final do arquivo "arquivo.txt". Se o arquivo não existir, ele será criado.
echo "Nova linha" >> arquivo.txt
Redirecionar a saída padrão e a saída de erro para arquivos diferentes, se houver mensagens de erro, elas também serão redirecionadas para o arquivo "erros.txt".
ls -l 2>&1 | tee saida.txt erros.txt
ln
- Código:
ln opções origem destino
- +informações:
- Cria links entre arquivos ou diretórios.
Existem dois tipos principais de links que o ln pode criar: links simbólicos (soft links) e links físicos (hard links).
Lembre-se de que links simbólicos podem atravessar sistemas de arquivos e apontar para qualquer caminho, enquanto links físicos só podem existir no mesmo sistema de arquivos que o arquivo original.
Opções Comuns:
-s Cria um link simbólico.
-b Cria uma cópia de backup se o destino já existir.
-f Força a criação do link, substituindo o destino, se necessário.
-i Pede confirmação antes de substituir arquivos existentes.
-n Trata o destino como um nome de diretório.
Este comando cria um link simbólico (soft link) para a pasta do jogo Grim Dawn, que é meu caminho de origem, ou seja, o diretório original que você desejo linkar.
E o outro caminho e meu destino, nesse caso o diretório drive_c, onde o link simbólico será criado.
A barra invertida \ no caminho do primeiro diretório é usada como um caractere de escape no shell para indicar que o espaço que a segue faz parte do nome do diretório ou arquivo, em vez de representar um separador de argumento.
ln -s /home/flyer2/.steam/steam/steamapps/common/Grim\ Dawn/ /home/flyer1/Downloads/grimdawn/wine/drive_c/
date
- Código:
date opções +formato
- +informações:
- Ele permite que você obtenha a data e a hora atuais, formate a saída de várias maneiras e realize cálculos com datas e horas.
Exibir a Data e Hora Atuais
date
Saída típica: sáb 18 mai 2024 19:01:03 -03
Você pode personalizar o formato da saída usando um sinal de mais +.
Exibe a Data e Hora usando uma saída formatada:
date +"%A %d %B %Y %H:%M:%S"
Saída: sábado 18 maio 2024 19:03:32
%Y: Ano com quatro dígitos.
%m: Mês (01-12).
%d: Dia do mês (01-31).
%H: Hora (00-23).
%M: Minuto (00-59).
%S: Segundo (00-59).
Mostra qual dia e hora seriam se passassem 62 horas e 59 minutos a partir da data atual:
date -d "+62 hours 59 minutes" +"%A %d %B %Y %H:%M:%S"
O que é um Timestamp Unix?
Um timestamp Unix é uma representação do tempo como o número de segundos que se passaram desde a meia-noite de 1º de janeiro de 1970, no horário UTC.
Esse ponto no tempo é conhecido como a "época Unix".
Como Usar um Timestamp Unix
Você pode usar o comando date no Linux para converter um timestamp Unix em uma data legível. Para isso, use o sinal de arroba @ seguido pelo timestamp:
date -d @1716080796
Timestamps são independentes de fuso horário, o que os torna ideais para sistemas distribuídos e aplicações que precisam manipular datas e horas de diferentes locais do mundo. Essa consistência evita ambiguidades relacionadas a formatos de data e hora específicos de regiões ou linguagens.
- Código:
x
- +informações:
- x
cal = Mostra um calendário
ldd = fornece uma lista das bibliotecas que são dependências compartilhadas/dinâmicas entre programas. ldd /usr/bin/cal
true = Crie uma saída em branco (nada é exibido) nada acontece.
reboot = Reinicia
shutdown now = desliga
Tem um site, onde você digita os comandos, e ele diz sua função: link
Maior parte desse programas se encontra no pacote da GNU coreutils
- abrir lista:
- /usr/bin/b2sum
/usr/bin/base32
/usr/bin/base64
/usr/bin/basename
/usr/bin/basenc
/usr/bin/cat
/usr/bin/chcon
/usr/bin/chgrp
/usr/bin/chmod
/usr/bin/chown
/usr/bin/chroot
/usr/bin/cksum
/usr/bin/comm
/usr/bin/cp
/usr/bin/csplit
/usr/bin/cut
/usr/bin/date
/usr/bin/dd
/usr/bin/df
/usr/bin/dir
/usr/bin/dircolors
/usr/bin/dirname
/usr/bin/du
/usr/bin/echo
/usr/bin/env
/usr/bin/expand
/usr/bin/expr
/usr/bin/factor
/usr/bin/false
/usr/bin/fmt
/usr/bin/fold
/usr/bin/head
/usr/bin/hostid
/usr/bin/id
/usr/bin/install
/usr/bin/join
/usr/bin/link
/usr/bin/ln
/usr/bin/logname
/usr/bin/ls
/usr/bin/md5sum
/usr/bin/mkdir
/usr/bin/mkfifo
/usr/bin/mknod
/usr/bin/mktemp
/usr/bin/mv
/usr/bin/nice
/usr/bin/nl
/usr/bin/nohup
/usr/bin/nproc
/usr/bin/numfmt
/usr/bin/od
/usr/bin/paste
/usr/bin/pathchk
/usr/bin/pinky
/usr/bin/pr
/usr/bin/printenv
/usr/bin/printf
/usr/bin/ptx
/usr/bin/pwd
/usr/bin/readlink
/usr/bin/realpath
/usr/bin/rm
/usr/bin/rmdir
/usr/bin/runcon
/usr/bin/seq
/usr/bin/sha1sum
/usr/bin/sha224sum
/usr/bin/sha256sum
/usr/bin/sha384sum
/usr/bin/sha512sum
/usr/bin/shred
/usr/bin/shuf
/usr/bin/sleep
/usr/bin/sort
/usr/bin/split
/usr/bin/stat
/usr/bin/stdbuf
/usr/bin/stty
/usr/bin/sum
/usr/bin/sync
/usr/bin/tac
/usr/bin/tail
/usr/bin/tee
/usr/bin/test
/usr/bin/timeout
/usr/bin/touch
/usr/bin/tr
/usr/bin/true
/usr/bin/truncate
/usr/bin/tsort
/usr/bin/tty
/usr/bin/uname
/usr/bin/unexpand
/usr/bin/uniq
/usr/bin/unlink
/usr/bin/users
/usr/bin/vdir
/usr/bin/wc
/usr/bin/who
/usr/bin/whoami
/usr/bin/yes
O site https://roadmap.sh disponibiliza guias para as principais linguagens de programação.
Você pode aproveitar esses guias para copiar os nomes das ferramentas necessárias para executá-las. Depois, basta fazer o download dessas ferramentas em seu sistema Linux.
VOLTAR AO TOPO VOLTAR AO ÍNDICEÚltima edição por ADRIANNO em Sáb 18 maio 2024, 7:50 pm, editado 31 vez(es)
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
PÁGINA 2
![]() por ADRIANNO Ter 07 Nov 2023, 1:32 pm
por ADRIANNO Ter 07 Nov 2023, 1:32 pm
VOLTAR AO ÍNDICE PRÓXIMA PÁGINAjournalctl
- Código:
journalctl parâmetro serviço
- +informações:
- journalctl é uma ferramenta para visualizar os logs do sistema no Linux, a partir da última inicialização.
Essas mensagens podem fornecer pistas para diagnosticar e corrigir algum problema.
Antes de iniciar uma investigação, é uma boa ideia reiniciar o sistema para garantir que irá analisar os logs desde o início.
Leia as mensagens de erro ou advertência que foram registradas durante a tentativa de iniciar o programa desejado.
Com base nas mensagens de erro ou advertência encontradas, você pode procurar por soluções online ou tentar diagnosticar o problema você mesmo.
Se necessário, você também pode compartilhar as mensagens de erro em fóruns de suporte para obter ajuda
O que ele pode exibir?
Linhas de Registro do Kernel
como a versão, opções de inicialização, informações do BIOS, configurações de memória, e outras informações relacionadas ao hardware.
Inicialização de módulos do kernel (como o vboxdrv), detecção de dispositivos de hardware (como o nouveau para placas gráficas), entre outros.
Informações do Sistema
como o fabricante do sistema, versão do BIOS, detecção da frequência do processador, configuração de proteção de execução de código, configurações de memória física e detalhes do hardware.
Mensagens de Aviso e Informação
como a presença de bugs no firmware, configurações do sistema que podem deixá-lo vulnerável a ataques de segurança (como o Spectre v2), e informações sobre módulos de kernel carregados.
Ele é útil para diagnosticar vários problemas que podem estar ocorrendo em seu sistema Linux.
Falhas de inicialização do sistema
Falhas de serviço
Problemas de permissões de acesso
Problemas de rede
Falhas de driver
Problemas de hardware
Conflitos de configuração de hardware
Problemas de segurança
Problemas de desempenho
Problemas de bibliotecas ou dependências
Vamos usar o comando na prática.
Visualizar logs de inicialização do sistema. Você pode adicionar o parâmetro -1 para visualizar os logs de inicialização da última inicialização, ou -k para visualizar logs do kernel.
journalctl -b
Exibe os registros do diário do usuário, que registram informações relacionadas às atividades do usuário no sistema.
journalctl --user
Isso mostrará as entradas de log do usuário a partir desse momento em diante.
journalctl --user --since="2024-03-16 12:00:00"
Visualizar logs de um intervalo de tempo específico. Este comando exibirá os logs do período de 14 de março de 2024, das 10:00 às 12:00.
journalctl --since "2024-03-14 10:00:00" --until "2024-03-14 12:00:00"
Visualizar logs de um serviço específico, -xeu significa que: queremos mostrar as mensagens de erro mais recentes no final (-e),
junto com detalhes adicionais (-x) e em formato legível por humanos (-u).
journalctl -xeu mariadb.service
Visualizar logs de um processo específico. Isso mostrará os logs associados ao processo com o ID 1234.
journalctl _PID=1234
Podemos filtrar os logs do sistema para exibir apenas as mensagens relacionadas ao XFCE.
Observando os logs do meu XFCE posso encontrar problemas nos serviços do DBus, identificar problemas de permissões incorretas.
journalctl -xe | grep -i xfce
Isso mostrará apenas as mensagens que contêm o termo audio
journalctl -xe | grep -i audio
Para visualizar os logs de um jogo sendo executado pela Steam, como o Civilization VI
journalctl -xe | grep Civilization
Mostra os logs do sistema em formato JSON, tornando mais fácil para análise programática ou processamento automatizado.
journalctl -o json-pretty
Fornece um resumo do espaço em disco ocupado pelos arquivos de log gerenciados pelo systemd-journald.
Ele mostra o tamanho total ocupado pelos registros de log, incluindo aqueles ativos e arquivados. Por exemplo:
os registros ocupam 418.9 megabytes no sistema de arquivos. Essa informação é útil para monitorar e gerenciar o espaço em disco.
journalctl --disk-usage
VOLTAR AO TOPO VOLTAR AO ÍNDICEÚltima edição por ADRIANNO em Sáb 16 Mar 2024, 1:08 pm, editado 3 vez(es)
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
ADRIANNO- Honrado
-
Mensagens : 796
Pontos : 6789
Reputação : 3
Data de inscrição : 12/01/2010
Cidade : Goiânia
Discord : adriano.dipaula#0406 -
Conteúdo patrocinado
Página 2 de 7 • 1, 2, 3, 4, 5, 6, 7

 Tópicos semelhantes
Tópicos semelhantes» Lista de Scripts em Shell Bash
» Lista de todos os jogos grátis na EPIC GAMES
» Jogando PW no Linux
» Grim Dawn no Linux
» (LINUX) Fallout 4 - Presets
» Lista de todos os jogos grátis na EPIC GAMES
» Jogando PW no Linux
» Grim Dawn no Linux
» (LINUX) Fallout 4 - Presets
Permissões neste sub-fórum
Podes responder a tópicos|
|
|